![[Next.js #40] MMD Clock AI Talk — LM Studio × VOICEVOX × MMDで「会話する時計アプリ」を作る](https://humanxai.info/images/uploads/nextjs-40-mmd-clock-ai-talk-lmstudio-voicevox.webp)
はじめに
今回は、これまで作ってきた MMD 時計アプリに 会話機能 を追加しました。
右下に会話 UI を追加し、入力欄からメッセージを送ると、MMD キャラクターが前中央へ歩いてきて、吹き出し と 音声 で返答します。 ローカル LLM には LM Studio、読み上げには VOICEVOX を使い、すべて Next.js アプリ内でつながるようにしました。
今回やりたかったのは、単なるチャット UI を置くことではありません。 メッセージ、音声、キャラクターの移動、吹き出し表示を一体化して、“時計の中に住んでいるキャラクター”として会話させること が目的でした。
結果として、かなり AI VTuber に近い体験が見えるところまで進みました。
前回の記事:

【Next.js #37】Three.js + MMD 時計アプリに動画壁紙を実装 — mp4をIndexedDBへ保存してループ再生する
Three.js + MMD ベースの時計アプリに動画壁紙機能を追加。mp4 を drag & drop で IndexedDB に保存し、Wallpaper UI 下に一覧表示、クリックで無音ループ再生、localStorage 連携による起動時復元、動画サ …
https://humanxai.info/posts/nextjs-37-threejs-mmd-clock-video-wallpaper-indexeddb/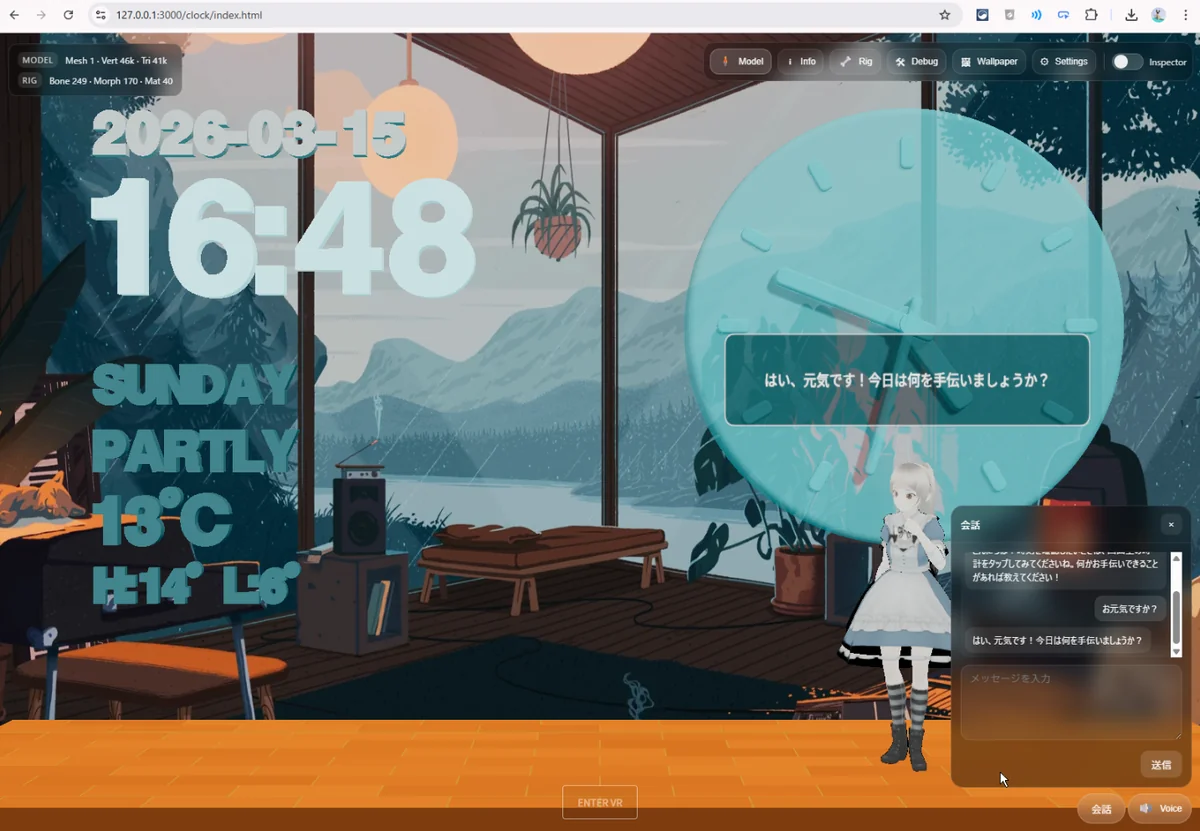
動画(YouTube):

Three.js x MMD AI Talk | Local LLM + VOICEVOX
MMD時計アプリに会話機能を追加しました。- LM Studio でローカルLLM応答- VOICEVOX で読み上げ- メッセージ送信でキャラが前に歩いて返答- 吹き出し表示にも対応Three.js / Next.js / MMD / ローカルLLM をつないで、AI VTuber風の体験を作っています。cre...
https://youtube.com/shorts/58sK8OVuNZQ?feature=share動画(PC):
何を作ったか
今回追加したのは、主に次の流れです。
- 右下に 会話ボタン と Voice ボタン を追加
- 会話パネルからメッセージ送信
- Next.js の API Route 経由で LM Studio に問い合わせ
- 返答テキストを会話ログに表示
- MMD キャラクターを 前中央へ歩かせる
- 返答内容を 吹き出し で表示
- VOICEVOX で返答を読み上げる
つまり、ただ返答文を画面に出すだけではなく、 キャラクターが前に出てきて、返事をして、実際に喋る ところまで統合しています。
これによって、UI の中に存在しているだけだったキャラが、 会話の主体としてちゃんと見えるようになりました。
なぜこの実装が面白いのか
普通のチャット UI は、テキストを入力して返答が返ってくるだけです。 それでも機能としては成立しますが、MMD キャラがいるアプリでは少し物足りません。
今回はそこを一歩進めて、
- 質問したら
- キャラが前に出てきて
- 吹き出しを出して
- 音声で返事する
という流れにしました。
この差はかなり大きいです。 単なる「チャット欄」ではなく、そこにいるキャラクターが応答している ように見えるからです。
MMD キャラを表示している以上、返答をテキストだけで完結させるよりも、
- 移動
- 向き
- 吹き出し
- 音声
までまとめて見せた方が圧倒的に面白いです。
時計アプリの中にキャラクターがいて、そのキャラがこちらへ歩いてきて返事をする。 この時点で、アプリの体験がかなり変わります。
実装の全体構成
会話 UI
まず右下に、会話ボタン と Voice ボタン を追加しました。
会話ボタンを押すとパネルが開き、
- 入力欄
- 送信ボタン
- 会話ログ
が表示されます。
ここは最初から LM Studio や MMD 演出をつながず、まずは UI だけ先に実装 しました。
- ボタン表示
- パネル開閉
- 入力できる
- 送信イベントが走る
- ログを表示できる
ここまでを先に確認してから、後で会話処理や音声をつないでいく形です。
この順番にしたことで、問題が起きた時に
- UI の問題なのか
- 会話処理の問題なのか
- 音声や LLM 連携の問題なのか
を切り分けやすくなりました。
VOICEVOX 連携
読み上げは voicevox.js としてまとめました。
このファイルでは主に、
- speaker 設定
- クレジット表記
- AudioQuery パラメータ
- ON / OFF 状態
speakText()による簡易呼び出し
を管理しています。
また、ブラウザの自動再生制限があるため、 右下に Voice ボタン を用意して、音声の ON / OFF を明示的に切り替える形にしました。
これによって、
- 音声が有効なのか
- まだ解除されていないのか
- 接続が通っているのか
が分かりやすくなりました。
最初は「音が出るかどうか分からない」という状態でしたが、 ボタン経由で有効化する形にしたことで、かなり扱いやすくなりました。
LM Studio 連携と CORS
ローカル LLM は LM Studio を使用しました。
最初はブラウザから直接 127.0.0.1:1234 に fetch() しようとしましたが、これは CORS で失敗しました。
VOICEVOX と同じで、ローカルに立っているサーバーでもポートが違えば別オリジン扱いになるため、そのままでは通りません。
そこで今回は、Next.js の API Route を使って
app/api/chat/route.js
を追加し、ここを LM Studio への中継 API にしました。
流れとしてはこうです。
- フロントの
chat.jsから/api/chatに送信 route.jsが LM Studio の OpenAI 互換 API を呼ぶ- 返答テキストだけをフロントへ返す
この構成にしたことで、フロントは同一オリジンの /api/chat にしかアクセスしないので、ブラウザ側の CORS 問題を回避できました。
ここは今回の実装の中でも、かなり重要なポイントでした。
会話処理の分離
ui.js はすでにかなり大きくなっていたので、会話処理そのものは chat.js に分けました。
役割としては、
ui.js→ 見た目、入力、パネル開閉、ログ描画chat.js→ 会話の送信、LLM 呼び出し、返答管理voicevox.js→ 音声読み上げroute.js→ LM Studio 中継
という構成です。
まだ完全に整理し切れているわけではありませんが、 少なくとも UI と会話ロジックを分ける方向 には持っていけました。
この分離をしておいたことで、あとから
- ダミー返答
- LM Studio 返答
- 口調制御
- 時刻回答
- キャラ演出
を足す時にかなり楽になりました。
MMD キャラクターの移動
今回の見せ場はここです。
もともと歩行ターゲット制御の基盤はあったので、前中央アンカーを利用して、 メッセージ送信時にキャラクターを前中央へ歩かせる 処理を追加しました。
これによって、会話が始まるとキャラが奥から前へ出てきます。
これだけでもだいぶ印象が変わります。 画面のどこかに立っているだけだったキャラが、会話に反応してこちらへ寄ってくるので、 「応答主体」が明確になります。
今回やりたかったのはまさにここで、 メッセージログと 3D キャラクターを分離させず、会話とキャラの行動を接続する ことでした。
吹き出し表示
移動だけではまだ足りないので、次に 吹き出し表示 を足しました。
LLM が返したテキストをキャラ頭上に出し、 会話ログだけでなく、3D 空間の中でも返答が見えるようにしています。
これによって、
- パネル内ログ
- キャラ頭上の吹き出し
- 音声読み上げ
が同時に成立し、返答内容がキャラクター自身のものとして見えやすくなりました。
この時点でかなり「AI VTuber感」が出てきます。
到着を待ってから話す処理
最初は、送信した瞬間に歩き出して、返答が来たらそのまま話す形でもよいかと考えていました。 ただ、やはり 前に来てから話した方が自然 です。
そこで、前中央アンカーとの距離を見て、 一定距離まで近づいたら吹き出しと音声を出すようにしました。
流れとしては次のようになります。
- ユーザーがメッセージ送信
- キャラが前中央へ歩く
- 裏で LLM 返答を取得
- 到着判定を待つ
- 到着後、吹き出し表示
- VOICEVOX で返答を読み上げる
これによって、会話体験がかなり自然になりました。
「歩いてきてから返事する」というだけで、 メッセージとキャラクターがかなり強く結びつきます。
実際にできあがったもの
ここまで実装した結果、
- 時計アプリ
- MMD キャラクター
- 会話 UI
- ローカル LLM
- ローカル音声合成
- 移動演出
- 吹き出し表示
が、ひとつの流れとして動くようになりました。
しかも今回はすべてローカルで動いています。
- LM Studio
- VOICEVOX
- Next.js
- MMD 演出
を全部ローカルでつなげて、 キャラクターに話しかけると前に出てきて返事する時計アプリ が成立しました。
ここまで来ると、もうただの時計アプリではありません。
ハマった点
今回ハマったところは主に次の3つです。
VOICEVOX の CORS
最初は 192.168.x.x 側で開いていたため、VOICEVOX Engine へのアクセスが通りませんでした。
127.0.0.1 で開くようにして解決しました。
LM Studio の直叩き
ブラウザから直接 LM Studio を叩こうとして CORS で止まりました。 Developer Mode を ON にするだけでは解決せず、 最終的に Next.js API Route 経由 に切り替えて通しました。
ui.js の肥大化
会話 UI 追加前から ui.js はかなり大きくなっており、今回さらに会話パネル、Voice ボタン、ログ表示などが追加されたため、リファクタ対象としてかなり意識するようになりました。
現時点では急ぎだったので全面分割していませんが、
今後は ui-chat.js などに抜いていく余地があります。
今回の実装で得たもの
今回いちばん大きかったのは、 「会話できるキャラクター」ではなく、「会話の主体として存在しているキャラクター」 に近づいたことです。
ログだけではなく、
- 前に出てくる
- 吹き出しを出す
- 音声で返す
という流れが入ったことで、会話がかなり立体的になりました。
これはかなり大きいです。
単なる API 接続や音声再生の確認ではなく、 キャラクターと UI と LLM を一つの体験に統合した ところまで来ました。
今後やりたいこと
今回の実装で土台はかなりできたので、次は質を上げる方向に進めそうです。
たとえば次にやりたいのはこのあたりです。
- system prompt を調整してキャラ性を強める
- 現在時刻や曜日をコンテキストとして渡す
- 時刻回答だけは専用処理にする
- 表情モーフやモーション切替を会話と連動させる
- 会話終了後に元の位置へ戻る
- 配信コメントを入力元にして AI VTuber 化する
今回で、 MMD × ローカル LLM × VOICEVOX × Next.js の組み合わせが十分成立することは確認できました。
ここから先は、返答の質だけではなく、口調、表情、移動、間の取り方まで含めて作り込んでいく段階になりそうです。
まとめ
今回は、MMD 時計アプリに会話機能を追加し、 LM Studio のローカル LLM と VOICEVOX を統合して、 キャラクターが前へ歩いてきて返答する AI 会話機能 を実装しました。
技術的には、
- 会話 UI
- ローカル音声
- Next.js API Route
- ローカル LLM
- MMD 移動演出
- 吹き出し表示
を接続した回でしたが、完成した体験としてはかなり面白いものになりました。
質問するとキャラクターがこちらへ歩いてきて、吹き出しを出しながら返事をする。 この時点で、かなり AI VTuber 的な体験 になっています。
次は、時刻や天気のような時計アプリ固有の文脈を返答に混ぜつつ、 さらに自然な会話演出へ寄せていきたいと思います。

ワンダープロジェクトJ 機械の少年ピーノ - Wikipedia
説明なし
https://ja.wikipedia.org/wiki/%E3%83%AF%E3%83%B3%E3%83%80%E3%83%BC%E3%83%97%E3%83%AD%E3%82%B8%E3%82%A7%E3%82%AF%E3%83%88J_%E6%A9%9F%E6%A2%B0%E3%81%AE%E5%B0%91%E5%B9%B4%E3%83%94%E3%83%BC%E3%83%8E
ワンダープロジェクトJ2 コルロの森のジョゼット - Wikipedia
説明なし
https://ja.wikipedia.org/wiki/%E3%83%AF%E3%83%B3%E3%83%80%E3%83%BC%E3%83%97%E3%83%AD%E3%82%B8%E3%82%A7%E3%82%AF%E3%83%88J2_%E3%82%B3%E3%83%AB%E3%83%AD%E3%81%AE%E6%A3%AE%E3%81%AE%E3%82%B8%E3%83%A7%E3%82%BC%E3%83%83%E3%83%88
💬 コメント