![[Next.js #26] Three.js×MMD:複数モデル表示とactor管理、順番トーク制御を実装](https://humanxai.info/images/uploads/nextjs-26-multiple-mmd-actors-sequential-talk-threejs.webp)
はじめに
前回、UI周りの実装を固め、MMDロード時に「モデル情報スナップショット」を生成。
![[Next.js #25] Three.js×MMD:モデル情報スナップショット→UI反映→デバッグ機能まで一気に固める](https://humanxai.info/images/uploads/nextjs-25-font-matter-ui-typography-threejs-mmd.webp)
[Next.js #25] Three.js×MMD:モデル情報スナップショット→UI反映→デバッグ機能まで一気に固める
Next.js×Three.js×MMDで作った3D時計に、上部ツールバー/右パネル/HUDを追加。UIが整った今こそフォント設計が効く。巨大な時刻表示、曜日/天気、HUD、パネルの階層を崩さず“作品っぽさ”を上げるためのフォント選定・スケー …
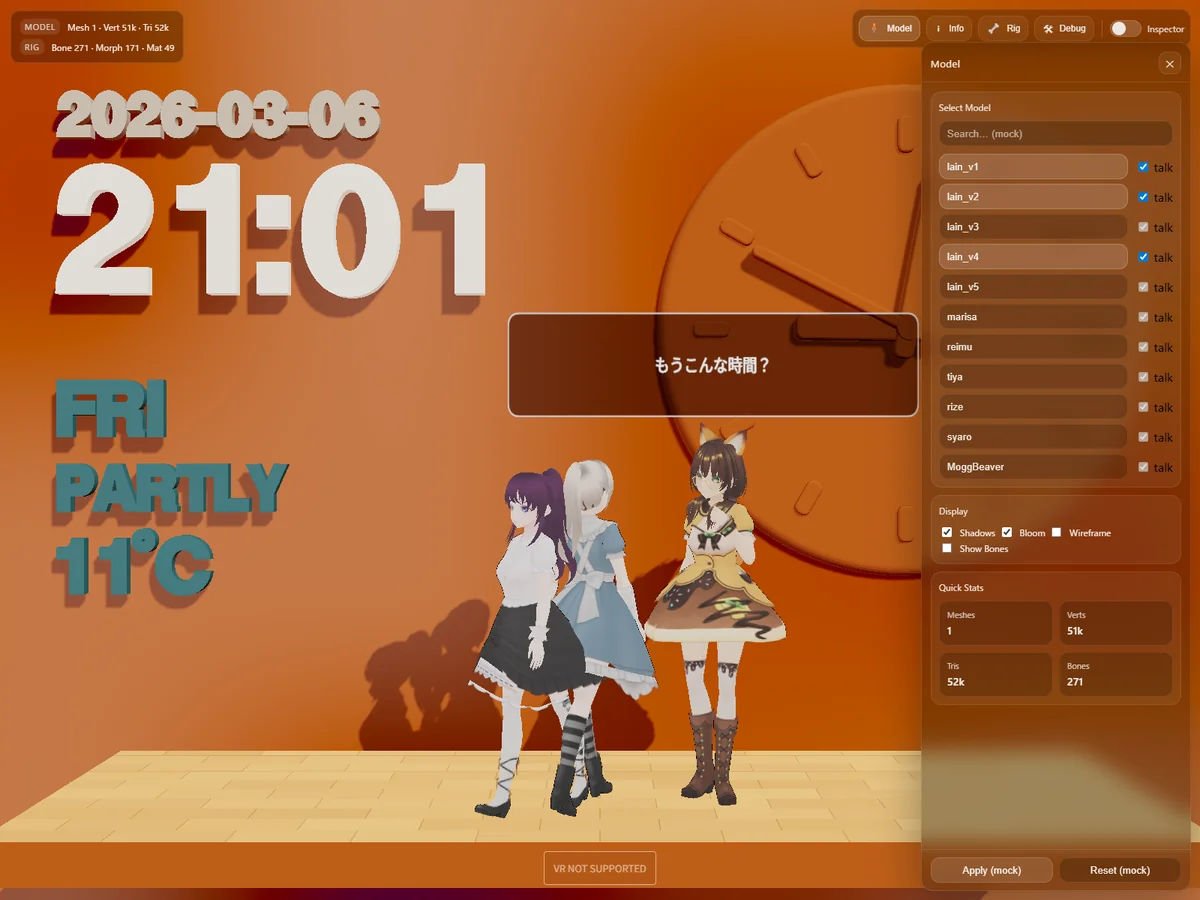
https://humanxai.info/posts/nextjs-25-font-matter-ui-typography-threejs-mmd/今回は、単体表示寄りだった構成を見直し、actors 配列で複数モデルを管理する形に変更し、 各 actor はそれぞれ独立した状態を持つようにし、以下を個別管理する構成に変更。
- id
- key
- pmxPath
- mesh
- helper
- walkAction
- walk
- talk
- selectedBone
これにより、モデルごとの状態分離が進み、今後の拡張もしやすい形へ拡張してます。
動画(YouTube):

Next.js × Three.js × MMD 複数モデル表示と順番トーク制御を実装 #short
今回は、MMD の複数モデル表示に対応し、actor ベースで各モデルを管理できるようにしました。あわせて、モデル追加 / 削除 UI、talk トグル、複数キャラを1人ずつ順番に喋らせる制御も整理しています。▼主な更新内容 - 複数MMDモデル表示 - actorごとの MMDAnimationHelper 分...
https://youtube.com/shorts/pVaXIBP_XV8?feature=share動画(PC):
actor ごとの MMDAnimationHelper 分離
これまで単体前提で扱っていた MMDAnimationHelper を、各 actor ごとに個別管理する構成へ変更した。
複数モデルを同時に表示する場合でも、アニメーション更新を actor 単位で安全に扱えるようになったのが大きい。
実装面では、モデル読み込み時に actor ごとに helper を生成し、VMD 読み込み後はそれぞれ専用の walkAction を保持するようにした。
また、updateMMD(delta) 内でも actor ごとに helper を更新する形へ整理し、単体構成に依存していた処理を切り離した。
この変更によって、複数体表示に向けたアニメーション基盤がかなり安定し、今後の拡張もしやすくなった。
モデル追加 / 削除 UI 対応
複数 MMD を前提とした UI に合わせて、モデルを動的に追加・削除できるようにした。 これにより、表示中の actor を固定せず、UI 操作から構成を切り替えられるようになった。
モデル追加
addActor(pmxPath) を実装し、最大 3 体までモデルを追加できるようにした。
追加時は PMX を読み込み、新しい actor を生成して scene と actors 配列へ反映する。
あわせて mmd:actors-changed を emit することで、UI 側も actor 構成の変化を検知できるようにした。
モデル削除
removeActorById(id) では、対象 actor を安全に破棄する処理を整理した。
actors 配列からの削除だけでなく、scene からの除去、sprite・material・geometry の dispose、helper からの remove まで行うことで、複数モデル運用時の後始末を一通りカバーしている。
さらに、primary actor の参照更新や、必要に応じた lastTalkActorId のリセットも加え、削除後の状態破綻を避けやすい構成にした。
この対応によって、複数モデルの追加・削除を含むライフサイクル管理が一通り揃った。
actor ごとの walk / talk 状態分離
複数モデルを同時に扱うため、walk と talk の状態も actor ごとに保持する構成へ整理した。 これにより、移動や発話の状態が単一グローバル変数に引きずられず、それぞれの actor を独立して制御しやすくなった。
walk
歩行状態は createActorWalkState() で生成し、各 actor が個別の移動設定を持つようにした。
ここでは、移動速度、移動可能範囲、到達判定用の半径、現在の目標地点、目標を持っているかどうかといった情報を保持している。
さらに updateActorWalk(actor, delta) を通して、actor ごとにランダムな移動先を持ちながら更新できるようにした。
この構成にしたことで、複数体が同時に存在していても、それぞれが独立して歩行できるようになった。
talk
発話状態についても createActorTalkState() を追加し、actor ごとに talk 用の状態を持たせるようにした。
保持する内容は、talk の有効 / 無効、吹き出し sprite、発話中フラグ、発話残り時間、次回発話までの待機時間、メッセージ配列、デフォルトポーズ、発話時間に関する設定など。
これによって、talk の ON/OFF、待機時間、発話内容、表示中の吹き出しといった要素をモデル単位で扱えるようになり、複数 actor を前提とした発話制御の土台が整った。
talk UI トグル対応
複数 actor を表示する構成にしたことで、モデルごとに talk の有効 / 無効を切り替えられるようにした。
単体前提のままだと、発話の ON / OFF は全体に対して一括でしか扱えず、特定のモデルだけ喋らせないといった制御がしづらい。
そこで setActorTalkEnabled(actorOrKey, enabled) を実装し、UI 側から actor ごとの talk 状態を直接切り替えられるようにした。
今回重要だったのは、単に enabled を切り替えるだけではなく、OFF にした瞬間の後始末まで含めて処理すること。
発話中の actor を途中で OFF にした場合、吹き出しや speaking 状態が残ったままだと、見た目だけでなく内部状態も崩れやすい。
そのため、OFF 時には scene 上の sprite を削除し、isSpeaking を false に戻し、speakTimer を 0 にし、次回発話までの nextDelay も再計算するようにした。
あわせて、停止していた walkAction も再開し、talk 中断後に歩行状態へ自然に戻れるようにしている。
この対応によって、UI 上の talk トグル操作が単なるフラグ変更ではなく、発話状態の停止処理まで含めた安定した切り替えとして機能するようになった。 複数 actor を前提にしたときの、地味だがかなり重要な整理ポイントだった。
複数 talk を 1 人ずつ順番に喋らせる制御を整理
今回の実装で大きかったのは、複数 actor がそれぞれ talk 状態を持てるようになったあと、実際にどう発話させるか を整理したことだった。 各 actor が独立した talk state を持っていても、そのままでは全員が同時に喋り始める可能性があり、画面としてかなり騒がしくなる。 そこで今回は、複数 actor が同時に喋るのではなく、有効な actor を順番に 1 人ずつ喋らせる 方針にした。
そのために lastTalkActorId を導入し、最後に実際に発話を開始した actor を記録するようにした。
さらに pickNextTalkActor() を用意し、次に発話させる actor を現在の候補一覧から選ぶようにしている。
候補に入るのは、mesh を持っていて、talk.enabled === true で、さらに entries に最低 1 件以上セリフがある actor のみ。
この条件にすることで、表示されていない actor や、talk が無効な actor、そもそも喋る内容を持たない actor は候補から除外できる。
巡回ロジック自体はシンプルで、lastTalkActorId が無ければ先頭 actor を選び、前回 actor が候補一覧にいればその次を選び、削除や OFF などで見つからなければ先頭へ戻すようにした。
こうしておくことで、候補 actor の増減があっても発話順が破綻しにくい。
updateMMD(delta) 側の流れもこの方針に合わせて整理した。
すでに発話中の actor がいる場合は、その actor だけに対して updateTalk を回す。
逆に、今は誰も喋っていない場合だけ pickNextTalkActor() で次の actor を選び、その actor の talk を進めるようにした。
この構成にしたことで、「同時に複数人が喋る」状態を避けつつ、複数 actor 間で発話を順番に回していく基本構造が整った。
lastTalkActorId の役割整理
lastTalkActorId は今回の順番制御の基準になる値だが、実装上はその意味をはっきりさせることが重要だった。
候補探索の途中で一時的に使う値ではなく、最後に実際に発話を開始した actor の id を保持する という役割に整理している。
この定義にしておくことで、pickNextTalkActor() は「前回本当に喋った actor の次」を選ぶだけでよくなり、ロジックが分かりやすくなる。
また、更新タイミングも startRandomTalk(actor) が成功したときのみに限定したため、「候補として見ただけの actor」や「実際には喋っていない actor」で lastTalkActorId が上書きされることも避けやすくなった。
さらに、actor 削除時には、その actor が lastTalkActorId と一致していれば null に戻すようにした。
これにより、削除済み actor を次回巡回時の基準にしてしまう不整合も防ぎやすくなった。
見た目は小さい変数だが、順番発話の基準点としてかなり重要な役割を持っている。
mmd-talk.js の actor 対応整理
もともとの mmd-talk.js は単体モデル前提の色が強く、内部で参照する mesh や walkAction も「現在の 1 体」を基準にした構成になっていた。
しかし複数 actor を扱うようになると、それでは誰に対する talk 処理なのかが曖昧になりやすい。
そこで mmd-talk.js 側も、各処理が actor 引数を受け取れるように整理し、talk 処理全体を actor 単位で扱えるようにした。
具体的には、getTalkState(actor) で対象 actor の talk state を取得し、getActorMesh(actor) や getActorWalkAction(actor) でその actor に紐づく mesh / walkAction を参照するようにした。
設定反映の applyTalkConfig(cfg, actor)、発話更新の updateTalk(delta, actor)、発話開始の startRandomTalk(actor)、吹き出し追従の updateTalkSpritePosition(actor)、発話中の視線制御である faceCameraSmooth(delta, actor) も、すべて actor を明示的に渡して処理する構成へ寄せている。
この整理によって、talk の内部処理が「どの actor に対する更新なのか」を常に明確に持てるようになった。 単体前提の実装ではグローバル参照に頼っていた部分が多かったが、actor 引数ベースに切り替えたことで、複数体表示でも talk 処理の対象がぶれにくくなった。 結果として、UI トグル、順番発話、個別ポーズ適用といった機能も actor ごとに自然につなげやすくなっている。
ポーズ適用の actor 対応
ポーズ適用処理も、単体モデル前提の実装から actor 単位で扱える構成へ整理した。
applyPose(name, actor) 形式にしたことで、対象となる actor を明示して VPD を適用できるようになり、複数モデル表示時でも「どのモデルにどのポーズを当てるのか」が分かりやすくなった。
従来の単体前提の構成では、ポーズ適用先が実質的に現在の 1 体に固定されやすく、複数 actor が存在する状況では扱いづらい。 今回の変更によって、発話中の actor に対してだけ talk 用ポーズを適用したり、モデルごとに異なるポーズを切り替えたりといった制御を自然に行えるようになった。
特に今回の talk 処理では、発話開始時に対象 actor ごとにポーズを当てる流れが必要になるため、この actor 対応は見た目の演出を維持するうえでも重要だった。 複数モデルを表示しつつ、発話 actor だけが適切なポーズを取るための基盤として機能している。
今日の到達点
- 複数 MMD 表示
- actor ごとの helper 分離
- actor ごとの walk / talk 状態分離
- UI からモデル追加 / 削除
- UI から talk ON/OFF
- 複数 actor の talk を 1 人ずつ順番に回す基盤整理
残作業
- talk の順番制御の実機確認
- talk 中 / 終了後の見た目やテンポ調整
- UI 上での状態表示の整理
- 複数体時のポーズ・移動・視線の細部調整
- 必要なら talk ボタンや選択 UI の拡張
💬 コメント