![[音声認識AI] Whisper(Python版)で高精度な音声文字起こし【GPU対応/ローカル実行】](https://humanxai.info/images/uploads/ai-whisper-python.webp)
🎙 Whisper(Python版)とは?
OpenAIが開発した高性能な音声認識モデル「Whisper」は、Python版でも提供されており、GPUを活かした高速な文字起こしが可能です。英語はもちろん、日本語を含む多言語に対応し、音声からの自動字幕生成や翻訳にも活用できます。
Whisper.cppに比べてインストールが容易で、Pythonを使うことで柔軟な自動化や前処理との統合もスムーズです。
![[音声認識AI] Whisper.cppを使って音声文字起こし【ローカル/オフライン/高精度】](https://humanxai.info/images/uploads/ai-whisper-cpp.webp)
[音声認識AI] Whisper.cppを使って音声文字起こし【ローカル/オフライン/高精度】
Whisper.cppをWindows環境にインストールし、音声ファイルから高精度な文字起こしをローカルで実行するまでの手順を解説します。Visual StudioとCMakeを使ったビルドから、日本語モデルの導入、実行例まで。インターネット接続なしでも動作 …
https://humanxai.info/posts/ai-whisper-cpp/1. インストール手順(Windows / Python仮想環境)
1.1 Python環境の準備(仮想環境推奨)
mkdir C:\AI
cd C:\AI
python -m venv venv
.\venv\Scripts\activate
1.2 GPU対応PyTorchのインストール(CUDA 12.1)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
※ GPUなし環境は pip install torch だけでOK
1.3 Whisperのインストール
pip install git+https://github.com/openai/whisper.git
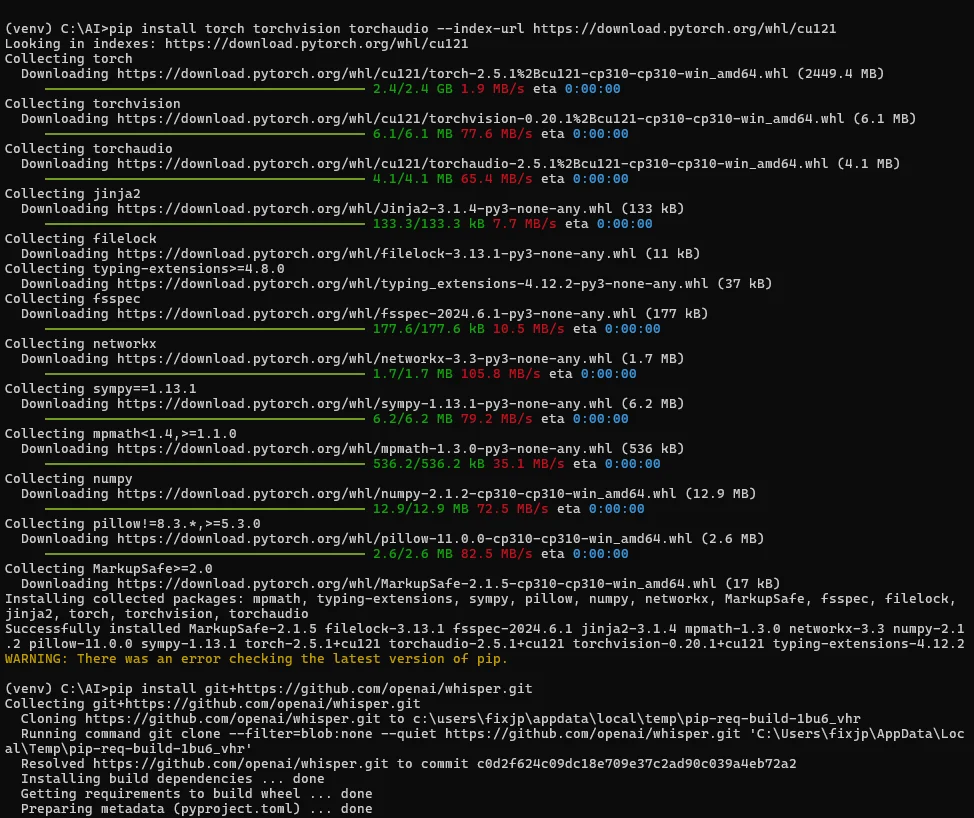
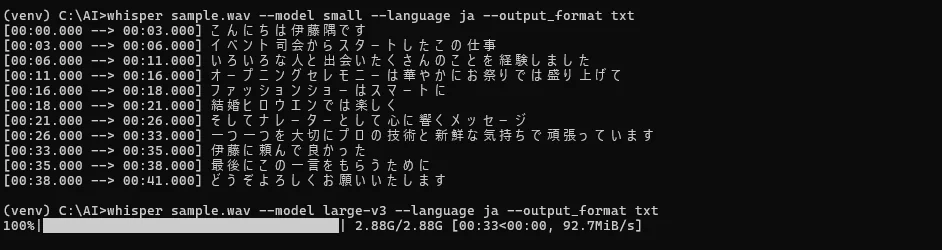
2. 実行とモデルの選択
whisper sample.wav --model large-v3 --language ja --output_format txt
- sample.wav: 入力ファイル
- –model: 使用モデル(tiny, base, small, medium, large-v3)
- –language: jaで日本語指定
- –output_format: txt, srt, vtt など対応
モデルは初回実行時に自動ダウンロードされます。
Whisper.cpp vs Whisper(python)
Pythonバージョンは、GPUを使用できるので、実行速度は劇的に早いです。
ただ、高性能な重いモデルを使用するとそれでも時間はかかります。
サンプル音声はここからお借りしています。

タイトル未取得
説明なし
http://www.arky.co.jp/service/studio_recording/voice_sample/samplevoice.htm3. モデルごとの精度と処理速度の違い
| モデル | 容量 | 精度 | 推奨環境 |
|---|---|---|---|
| tiny | ~75MB | 低 | 軽量CPUでもOK |
| small | ~500MB | 普通 | 日常会話程度 |
| medium | ~1.5GB | 高 | 長文・文脈重視 |
| large-v3 | ~3GB | 非常に高 | GPU推奨、句読点も自然 |
large-v3 + GPUなら、数十秒の音声が数秒〜10秒以内に処理完了!
4. バッチファイルで自動化(xxx.bat)
以下のようにして .wav と同じフォルダに文字起こし結果を出力可能:
@echo off
if "%~1"=="" (
echo 使用方法: whisper-ja.bat ファイル名.wav
pause
exit /b
)
cd /d "%~dp1"
call C:\AI\venv\Scripts\activate.bat
whisper "%~nx1" --model large-v3 --language ja --output_format txt
pause
whisper-ja.bat sample.wav のように使えば、同じ場所に sample.txt が出力されます。
5. まとめと今後の応用
- Whisper(Python版)は高精度かつ高速な音声文字起こしが可能
- ローカル・オフライン環境で動作するため、セキュアでプライバシーも安心
- GPUがあれば
large-v3でも実用的に運用可能
今後の応用例
- YouTube動画の文字起こし・翻訳・字幕生成
- 音声コーパスの構築や機械学習前処理
- 自動議事録や取材音源の文字化処理
Pythonを使うことでさらに柔軟な自動化が可能なので、WhisperをローカルAI音声認識の第一歩にぜひ活用してみてください!
💬 コメント