![[音声LLM]清水亮さん作のローカル音声LLM UI(voicellm)をWInodwsで動かす](https://humanxai.info/images/uploads/ai-voicellm.webp)
はじめに
今朝、shi3z show(清水亮)氏のYoutubeチャンネルを見ると、ローカル音声LLM UI(voicellm)を作成したとの事で、Mac環境で作成し、Winodwsで試してないそうなのでインストールして興味本位で動かしてみましたので、その備忘録メモです。
GitHub - shi3z/voicellm
Contribute to shi3z/voicellm development by creating an account on GitHub.
https://github.com/shi3z/voicellmshi3z show(清水亮)氏については、Wikipediaなど。

清水亮 (実業家) - Wikipedia
説明なし
https://ja.wikipedia.org/wiki/%E6%B8%85%E6%B0%B4%E4%BA%AE_(%E5%AE%9F%E6%A5%AD%E5%AE%B6)1) 事前準備(Windows)
- Python 3.8+(3.10〜3.12でOK)をインストール
- Git をインストール
- Node.js(後でツールを動かす予定があれば)
- LM Studio(Windows版) を入れておく → アプリの設定で OpenAI互換API を ポート1234 で有効化、好きなモデルをロード(例: GPT-OSS, Qwen, Gemma など (LM Studio) (GitHub)
- ブラウザは Chrome / Edge を推奨(マイク権限&Web Speech API/TTSの相性が良い)
補足:このプロジェクトはブラウザ内WASMの sherpa-onnx で音声認識を回す設計。つまりポータブルで、PortAudioなどのOS依存ドライバは不要。 (GitHub)
Node.jsまでは終わってるのでgit clone からやっていきます
2) クローン & 依存関係
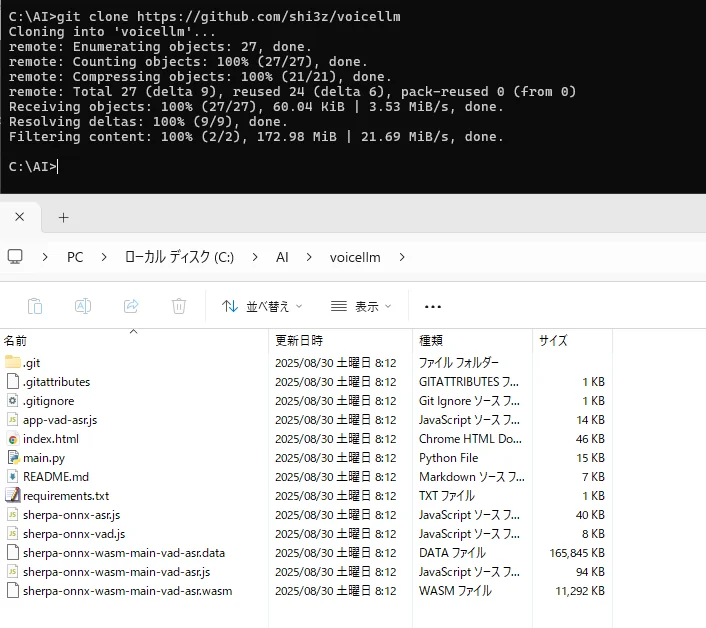
git clone https://github.com/shi3z/voicellm
cd voicellm
# まずは最小限(Flask ほか)
python -m pip install --upgrade pip
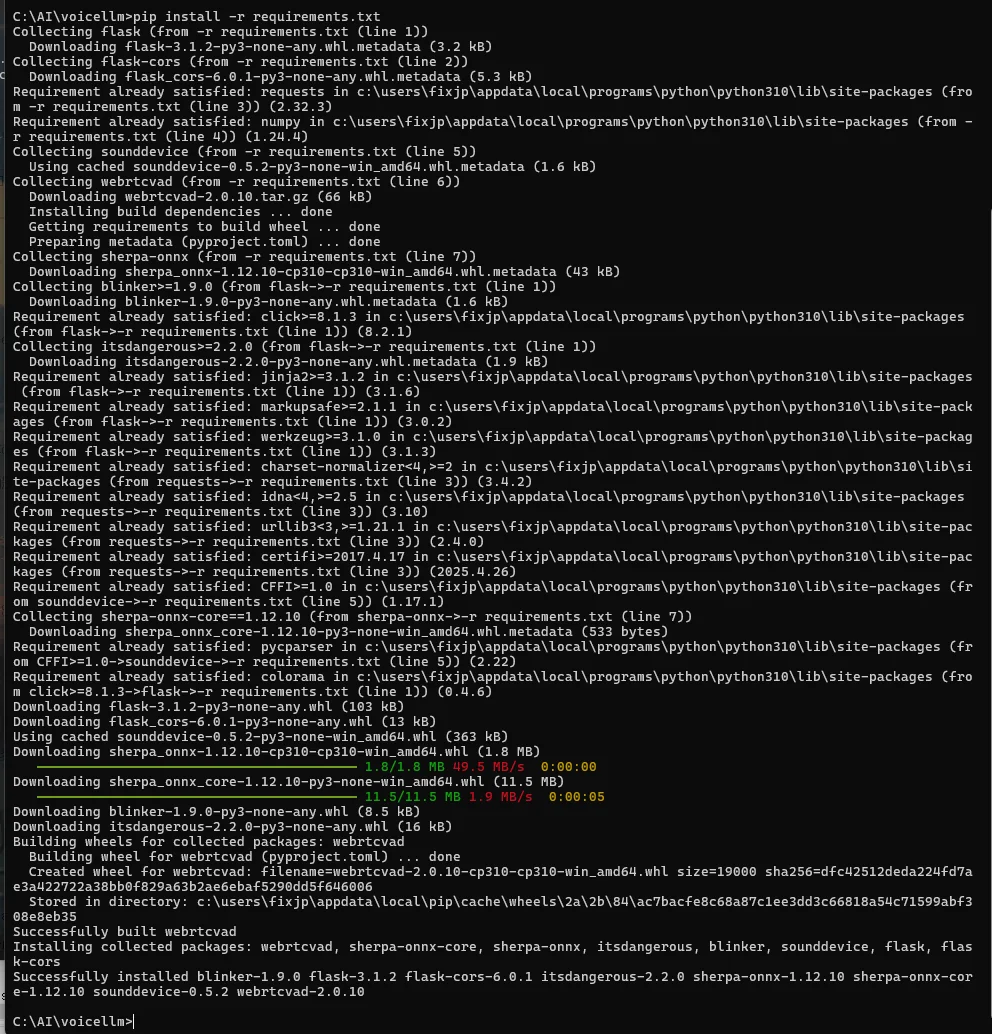
pip install -r requirements.txt
requirements.txt で引っかかったときは、まず Flask, requests, flask-cors だけ入れてサーバが立つか試すと早い。 (GitHub)
3) LM Studio 側の起動チェック
![[GPT-OSS] OpenAI公式 OSS LLM『GPT-OSS』を ローカルで動かす(Ollama /LM Studio)](https://humanxai.info/images/uploads/gpt-oss-01.webp)
[GPT-OSS] OpenAI公式 OSS LLM『GPT-OSS』を ローカルで動かす(Ollama /LM Studio)
GPT-OSS 20Bをローカル環境にインストールし、Ollamaで実行する手順をまとめた備忘録。環境構築の注意点、モデルの取得方法、エラー対処、実際の動作確認まで、初心者にもわかりやすく解説しています。
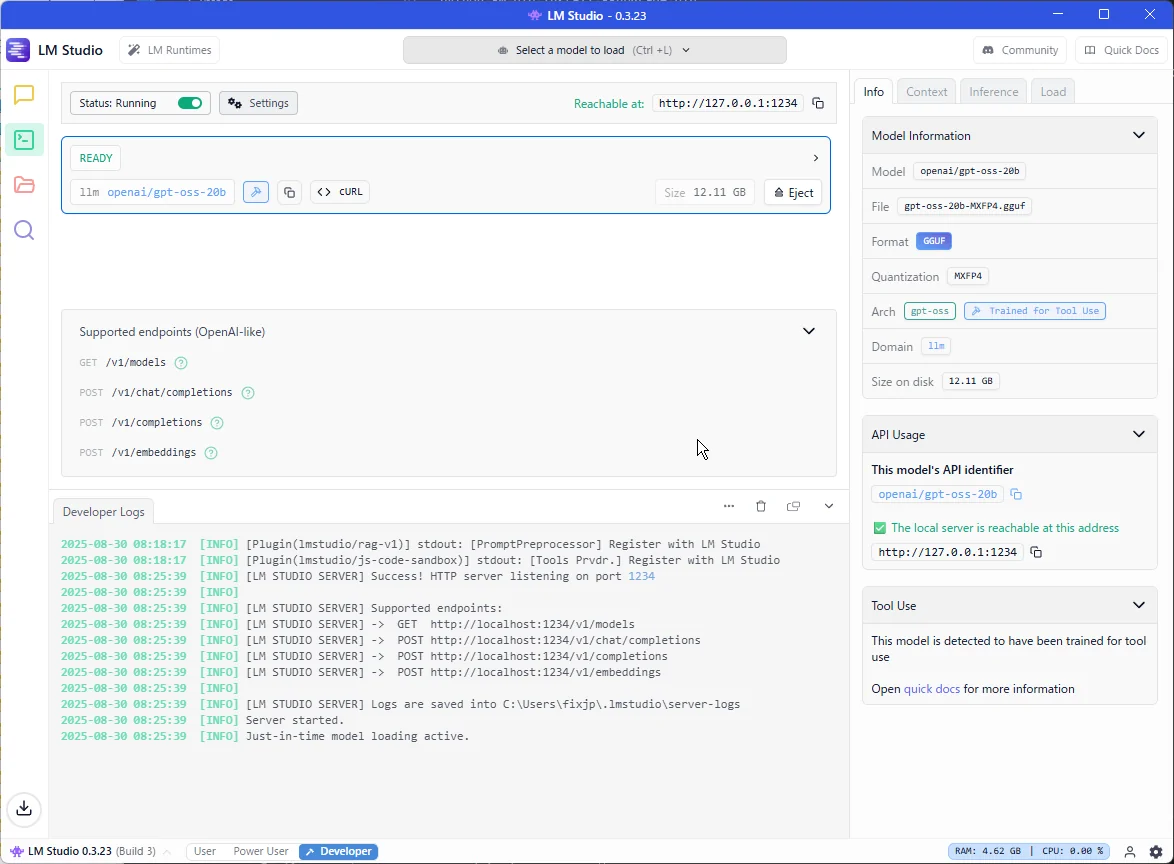
https://humanxai.info/posts/gpt-oss-01/- LM Studioでモデルをロード
- 「OpenAI compatible API」をオン(ポート: 1234)
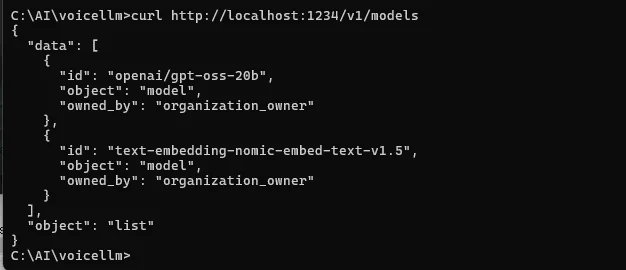
- 確認:
:contentReference[oaicite:5]{index=5}
JSONでモデル名が返ればOK。(GitHub)
4) アプリ起動
python main.py
- 既定で http://localhost:8000 が開く(開かない場合はブラウザで手動アクセス)。
- 画面右上の設定で モデル名(LM Studioでロードしたもの)を選択。
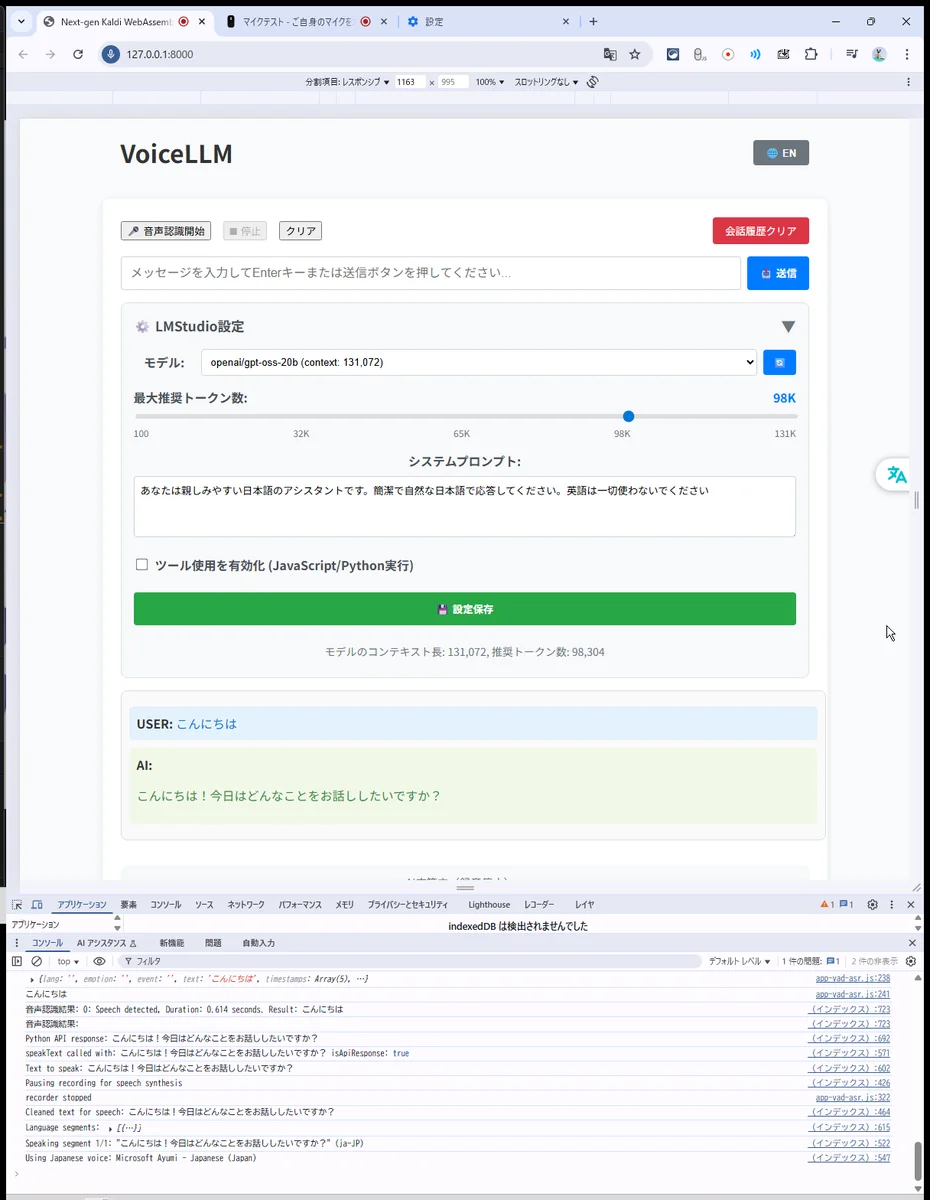
- Start を押して話しかけ → 文字起こし → 返答 → 音声合成まで流れを確認。(GitHub)
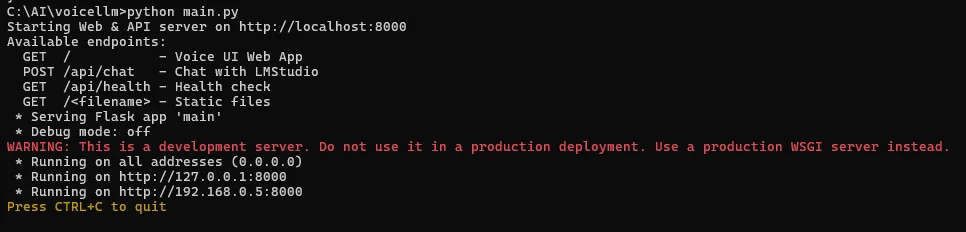
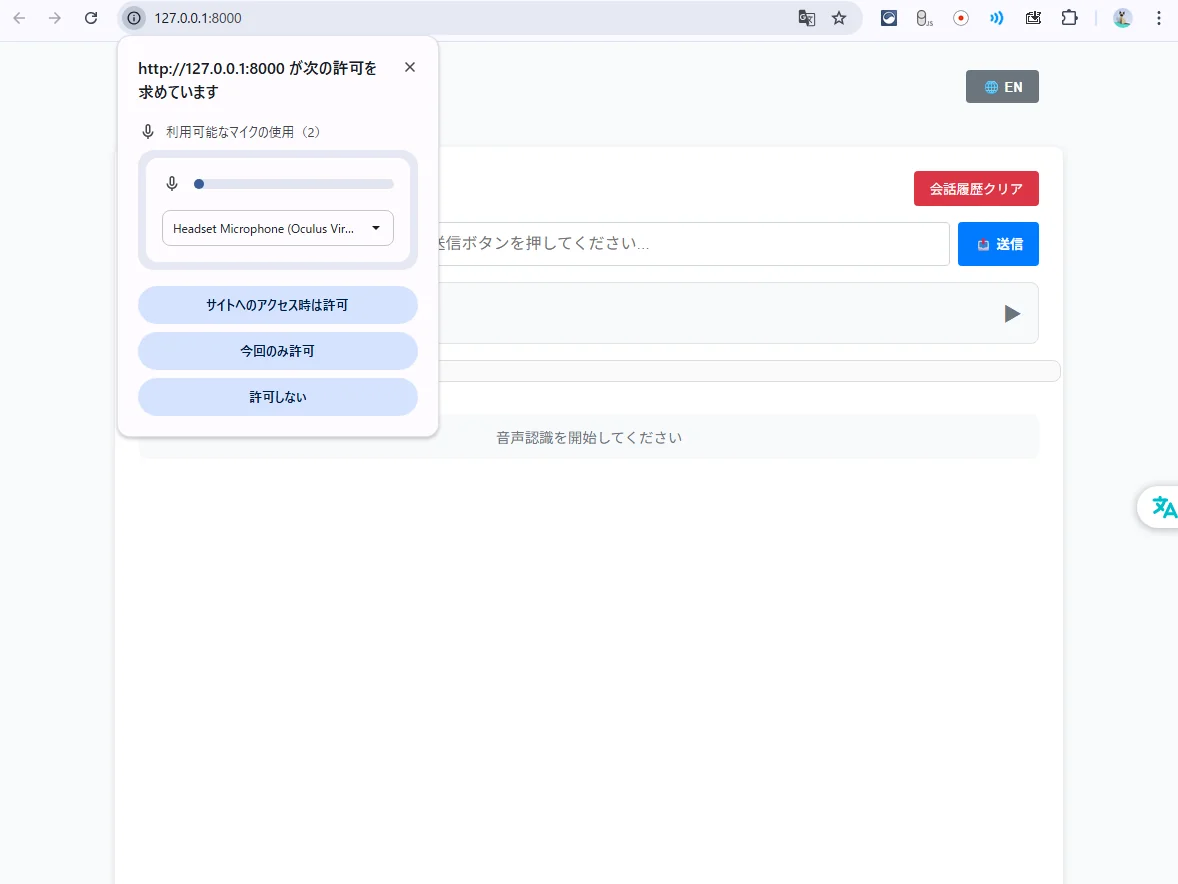
接続先をvoicellmに教える
(UIに設定項目がなければ、環境変数 or .env で指定)
set LLM_API_BASE=http://127.0.0.1:1234/v1
set LLM_MODEL=openai/gpt-oss-20b
set LLM_API_KEY=lm-studio rem ダミーでOKな実装向け
python main.py
ここまでで、一応動きましたが、マイクが認識されず、チャットで音声読み上げは動いています。
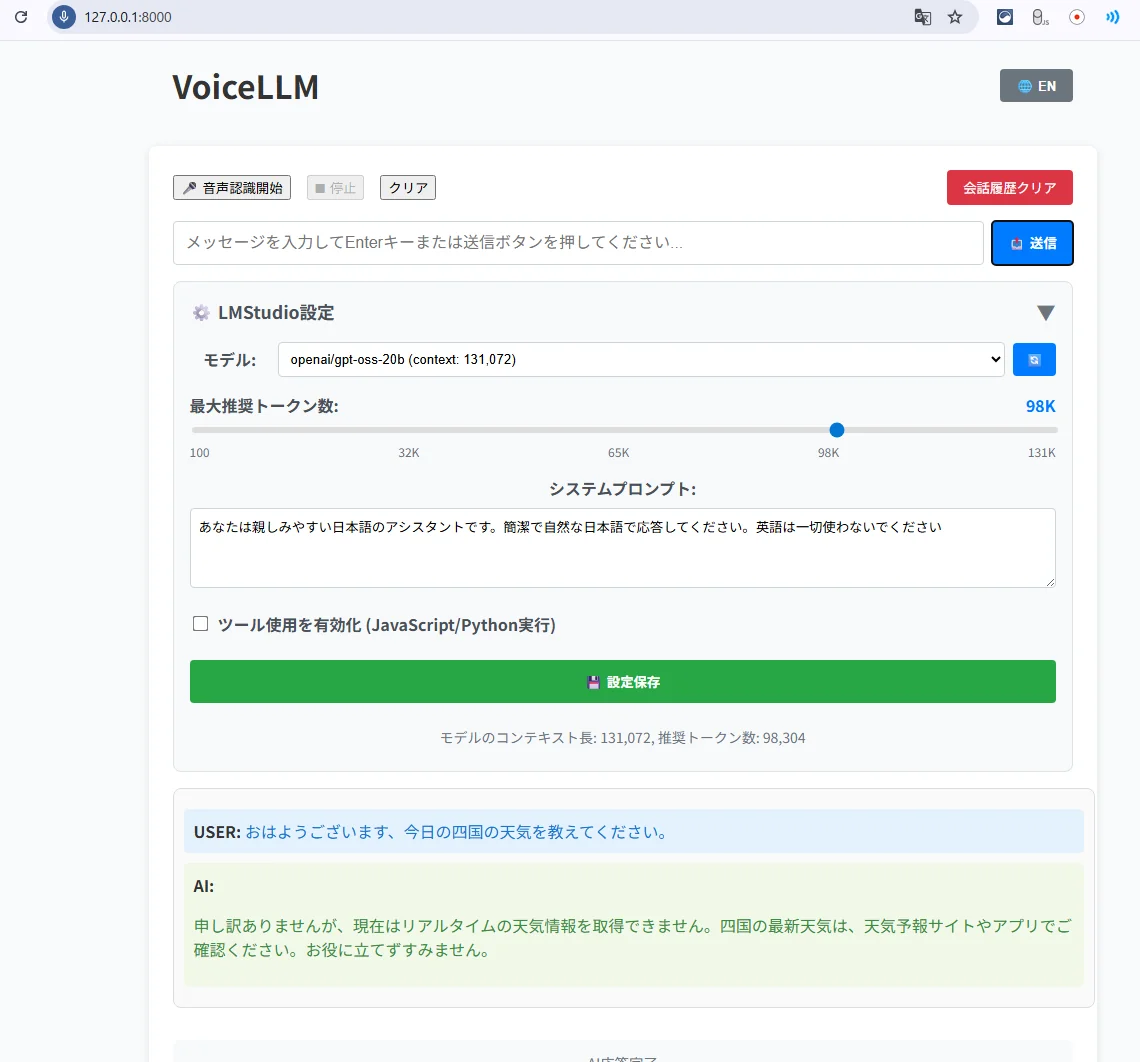
マイク確認
ブラウザが拾ってるデバイスの確認。
F12 → Console で下を貼り付け:
navigator.mediaDevices.enumerateDevices().then(d => console.log(d))
どのデバイスが “default” 扱いになっているか分かる。
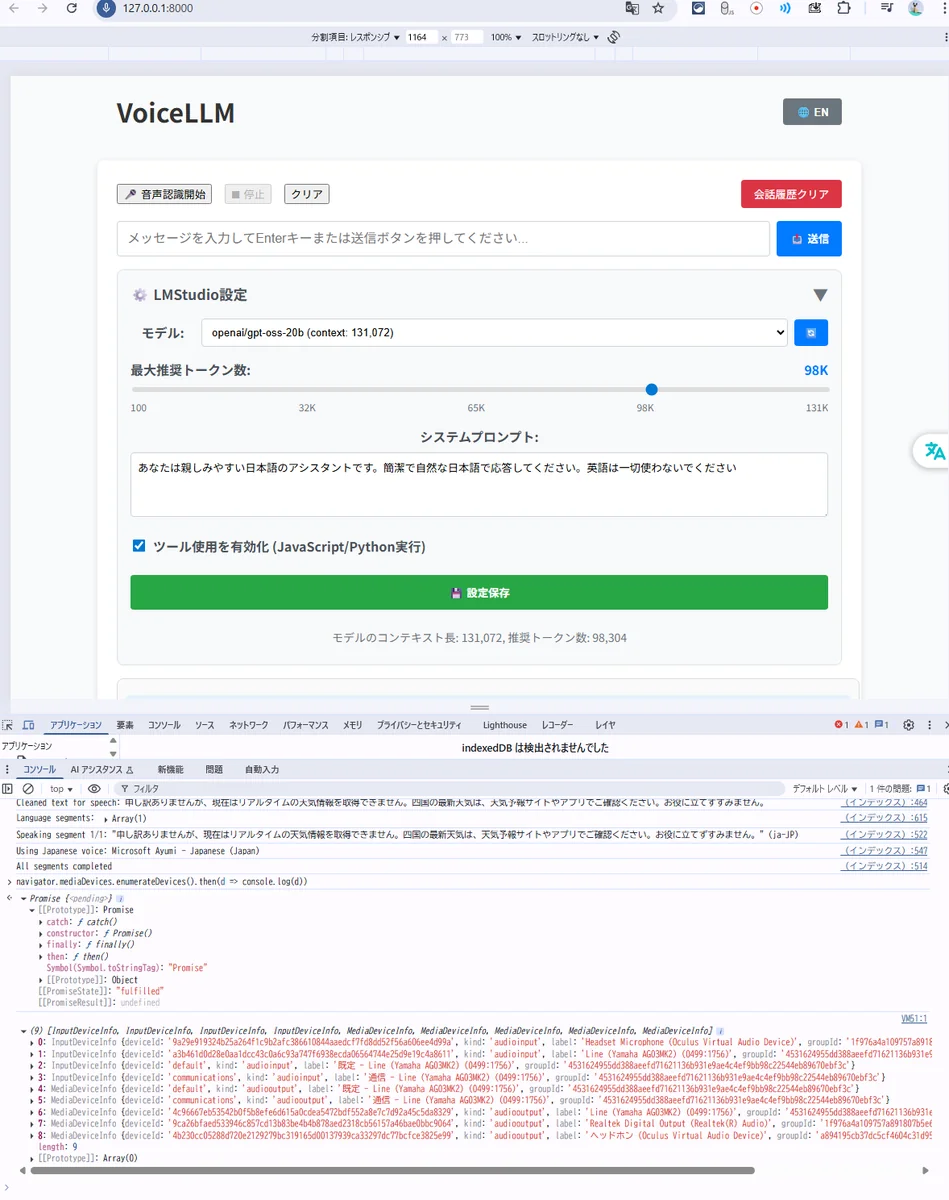
特定のマイクを強制する方法
A) OSの既定デバイスを変える(最速)
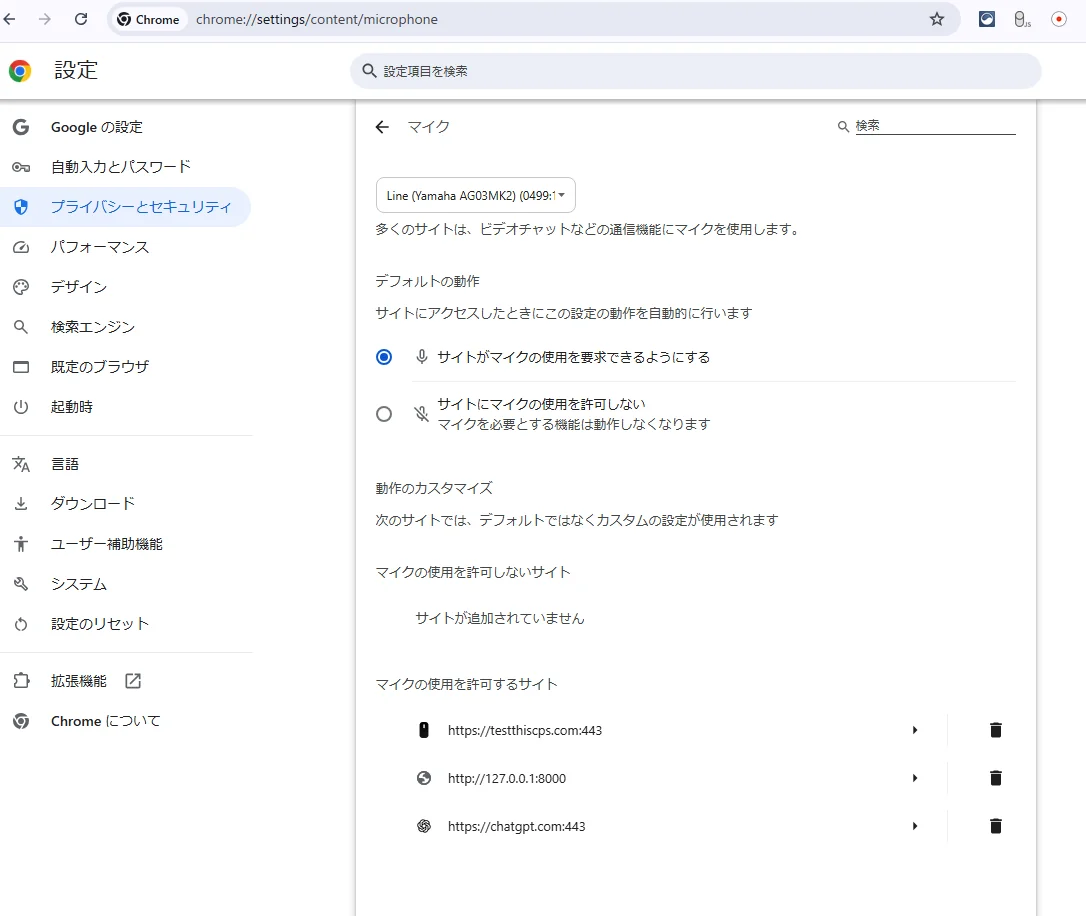
Windows の「サウンド > 入力 > 既定のデバイス」を AG03 などに変更 → ページを再読込 → 「音声認識開始」。
これで {audio:true} でも狙いのマイクを掴みます。
B) JSを少し改造(確実)
{audio:true} を、列挙した deviceId を使う形に差し替えます。
下のパッチで、ラベルに “Yamaha” を含む入力を優先して使う例です(無ければ既定にフォールバック)。
置き換えポイント:if (navigator.mediaDevices.getUserMedia) { … } ブロック全体を以下に差し替え
if (navigator.mediaDevices && navigator.mediaDevices.getUserMedia) {
console.log('getUserMedia supported.');
// 1) まず一度だけ権限を取りに行く(ラベル取得のため)
// 既に許可済みなら即resolveされる
await navigator.mediaDevices.getUserMedia({ audio: true })
.then(s => s.getTracks().forEach(t => t.stop()))
.catch(err => console.warn('pre-permission getUserMedia failed:', err));
// 2) デバイス列挙して、使いたいマイクを選ぶ
const devs = await navigator.mediaDevices.enumerateDevices();
console.log('devices:', devs);
// 例: ラベルに "Yamaha" を含む入力を優先
const preferred = devs.find(d =>
d.kind === 'audioinput' && /yamaha/i.test(d.label)
);
const constraints = preferred
? { audio: { deviceId: { exact: preferred.deviceId } } }
: { audio: true }; // フォールバック(既定デバイス)
// 3) 選んだconstraintsで本番ストリームを取得
navigator.mediaDevices.getUserMedia(constraints).then(onSuccess, onError);
} else {
console.log('getUserMedia not supported on your browser!');
alert('getUserMedia not supported on your browser!');
}
もし特定IDを固定したいなら:
preferred の代わりに const constraints = { audio: { deviceId: { exact: “ここにdeviceId” } } }; と直指定でOK。
deviceId は enumerateDevices() の結果(さっきのスクショのやつ)を貼る。
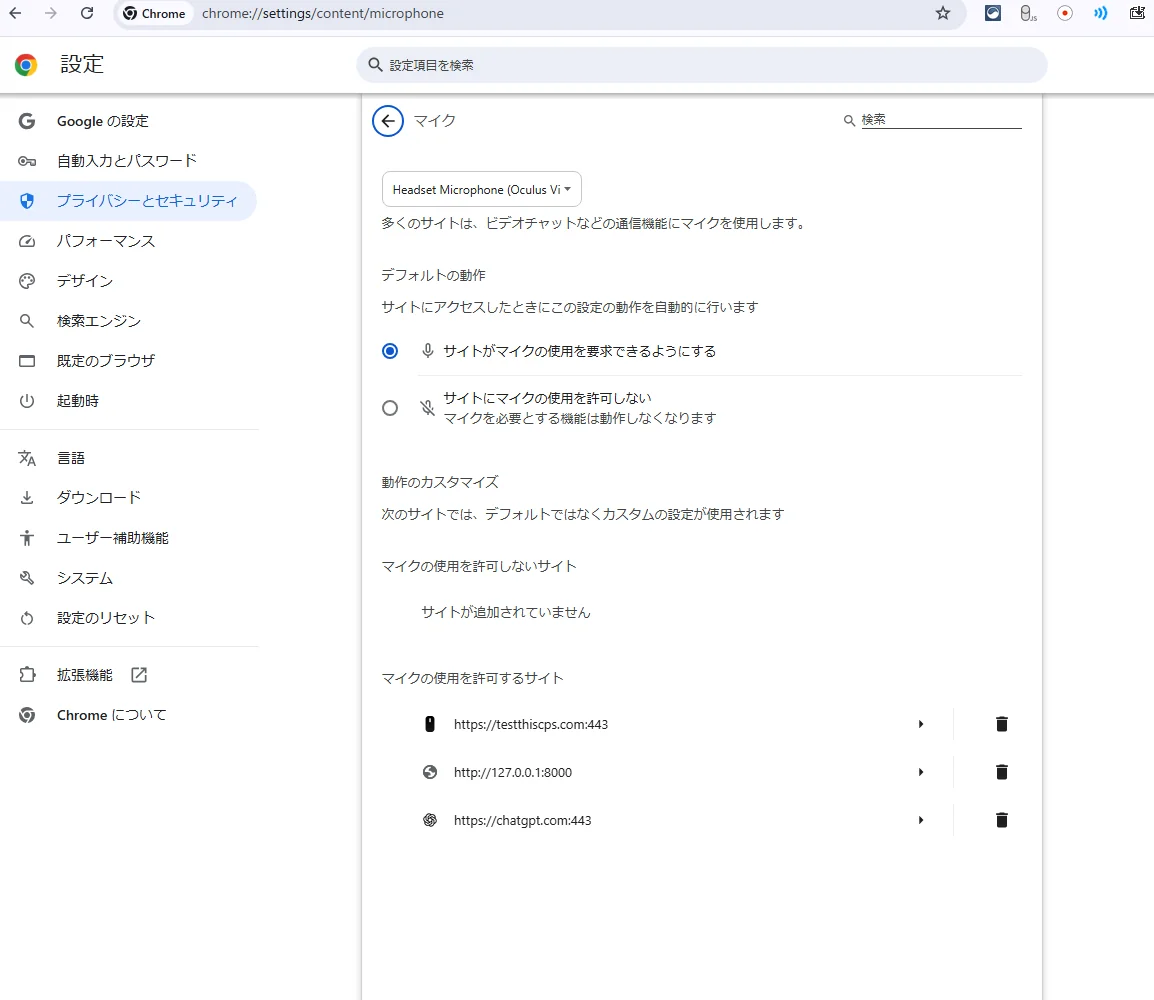
Chromeのマイク設定
chrome://settings/content/microphone
ここが原因で、マイクを認識しなかったようです。
デバイスが「Oculus」になってる。
変更後
動作確認
5) Windows特有の詰まりポイント対処
-
マイクが取れない:ブラウザのアドレスバー右端の🔒/マイクから許可。OSの「プライバシーとセキュリティ > マイク」でアプリ(ブラウザ)を許可。 GitHub
-
音が出ない / 日本語TTSが不自然:Windowsの「言語と地域」で日本語の音声パックを追加。Web Speech APIの声はOS依存なので、音声パックがないと英語声に倒れる。 GitHub
-
ポート8000使用中:READMEの手順通りプロセスを落とす(Windowsなら netstat -ano | find “:8000” → 該当PIDをタスクマネージャで終了)。 GitHub
-
LM Studioに繋がらない:APIをオンか再確認、http://localhost:1234/v1/models が返るかを必ず確認。 GitHub
-
ASR(音声認識)が反応しない:同梱の sherpa-onnx-wasm-*.wasm/js/data が正しく配信されているか、ブラウザのコンソールでWASMロードエラーがないかを確認。失敗時はブラウザの音声認識にフォールバックする設計。 GitHub
6) 仕組みの確認(ざっくり)
- 音声入力:ブラウザで sherpa-onnx(WASM)+VAD → テキスト化
- 会話:FlaskのAPIから LM Studio のOpenAI互換APIへ投げる
- 出力:テキストは画面表示、音声はWeb Speech API でTTS(日本語/英語自動切替)
- ツールコール:設定でJS/Pythonの小さなコード実行も可能(サンドボックス&タイムアウト)。 GitHub
7) 動作保証の現状(参考)
Zennに**「Macで試した」**記録があり、完全ローカルで会話できるがレスポンスはやや重めという所感。作者本人もまずはMacで試している様子。ただし、上の通り構成はOS非依存なのでWindows検証の価値は高い。 Zenn GitHub
8) うまく行かない時の切り分けリスト(最短で原因特定)
- LM Studio API:/v1/models が返るか
- Flask API:http://localhost:8000/api/health が 200 か(READMEのエンドポイント一覧に記載) GitHub
- ASR:ブラウザコンソールで sherpa-onnx の読み込みエラー有無
- TTS:Web Speech APIの音声リストを speechSynthesis.getVoices() で確認(日本語音声があるか)
- CORS:LM Studio APIに外部から投げる時は、同一ホスト/ポートで叩けているか
9) 代替・拡張のヒント(任意)
-
Web Speechの声質が微妙なら、Piper TTS 等のローカルTTSに差し替える拡張もあり(別途HTTPブリッジが必要)。 YouTube
-
LM Studioの代わりにOllamaを使う場合は、OpenAI互換のエンドポイントに合わせて main.py のAPI先を切り替える改造でいける(リクエスト形式はOpenAI互換に揃える)。※元READMEはLM Studio前提。 GitHub
まとめ
結論:Windowsでも動く構成。要は「LM StudioのOpenAI互換APIが生きてること」「ブラウザがWASM+マイク+Web Speechを通すこと」の2点が通ればOK。 (GitHub) (LM Studio)
関連リンク
GitHub - shi3z/voicellm
Contribute to shi3z/voicellm development by creating an account on GitHub.
https://github.com/shi3z/voicellm
shi3z|note
ハッカー / テクニカルエンスージアストUberEats配達員(多忙のため休業中)
https://note.com/shi3zblog
💬 コメント