![[画像生成AI] Gemini 2.5 Flash Image 画像生成&編集の最新体験レポート](https://humanxai.info/images/uploads/ai-gemini2_5-flash-image.webp)
1. はじめに:Gemini 2.5 Flash Imageとは?
2025年8月、Google が公開した最新の AI 画像生成・編集モデルが 「Gemini 2.5 Flash Image」 です。開発コードネームは「nano-banana」。名前こそユニークですが、その実力は非常にまじめで、従来の生成モデルから大きく進化しています。
このモデルの特徴は大きく3つに集約されます。
-
マルチ入力画像の融合 複数の画像を組み合わせて新しいイメージを生み出すことが可能。例えば「家具写真」と「空室の部屋画像」を組み合わせて完成イメージを生成する、といったプロフェッショナルな使い方もできます。
-
キャラクターやスタイルの一貫性保持 同じ人物やキャラクターを、異なるシーンやポーズに配置しても、顔や服装の特徴を保ったまま描き出すことができます。これまでの生成モデルでは崩れがちだった「キャラの安定感」が一気に改善しました。
-
自然言語による対話型編集 「背景を少しぼかして」「服の色を青に変えて」といった会話形式の指示を、そのまま反映できます。Photoshop のようなレイヤー操作を知らなくても、自然な日本語で修正依頼ができるのが大きな強みです。
では、なぜ今このモデルが注目されているのでしょうか? 理由はシンプルで、“低レイテンシ”と“高品質”を両立しているからです。生成が速く、かつ安定感のある出力が得られるため、クリエイターにとっては「待ち時間ストレスの少ない相棒」となります。
さらにすでに Adobe Firefly や Adobe Express といったメジャーなツールに統合され始めており、今後ますます利用シーンが広がることが予想されます。AI 画像生成の次のスタンダード候補として、一気に存在感を高めているわけです。
👉 次章では、このモデルを実際にどう触れるのか、セットアップと利用環境について整理していきましょう。
2. セットアップと利用環境
では実際に Gemini 2.5 Flash Image をどうやって使えるのか。 現時点での主な利用環境は、大きく3つに分かれます。
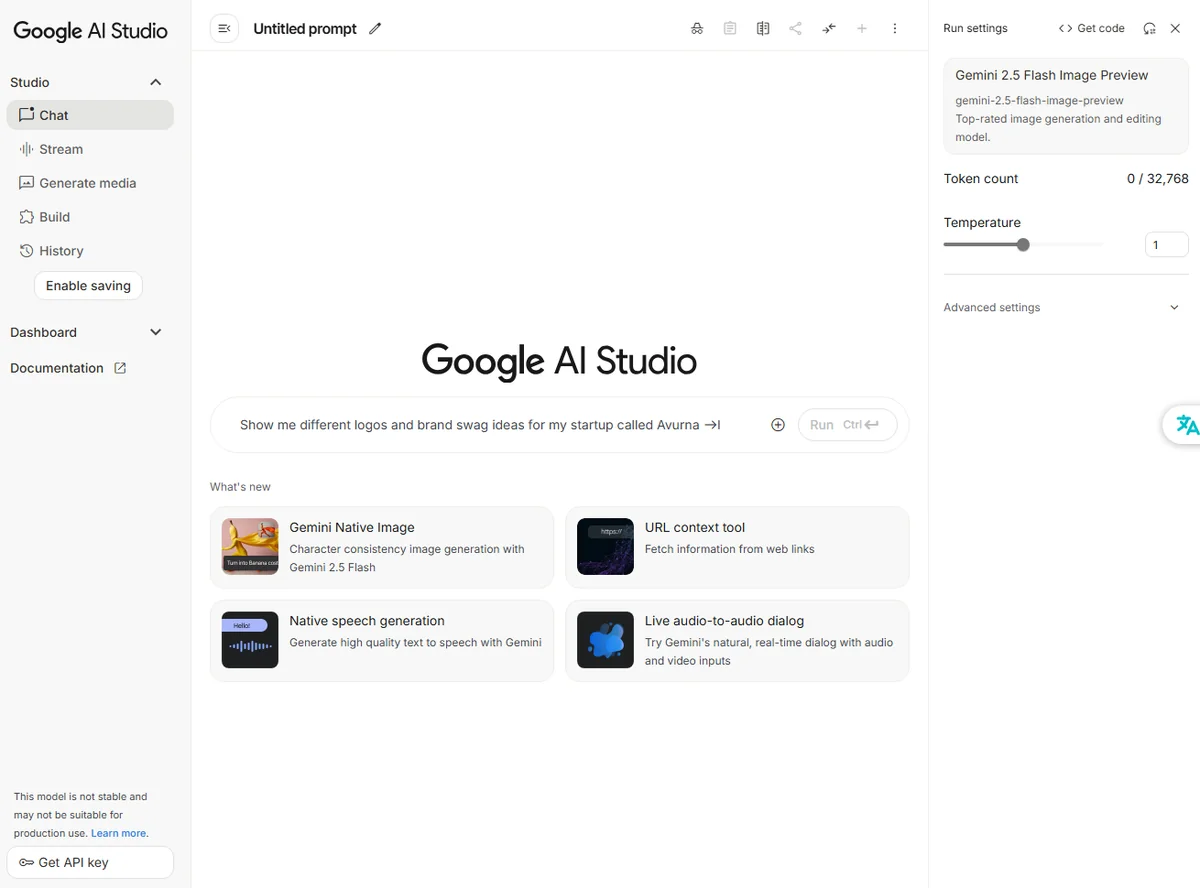
(1) Google AI Studio
最も手軽に試せるのが Google AI Studio です。 ブラウザから直接アクセスでき、プロンプトを入力してすぐに画像生成や編集を体験できます。サンプルも豊富で、「背景のぼかし」「オブジェクトの削除」「人物の服装変更」などのテンプレートがあらかじめ用意されているのが魅力です。 → 「とにかくまず触ってみたい」という人には、このルートがおすすめです。
(2) Vertex AI(Gemini API)
開発者や企業利用を想定するなら、Google Cloud の Vertex AI で提供される Gemini API が選択肢になります。 こちらは コードから直接画像生成や編集を呼び出せるため、自作アプリやワークフローに組み込みたい人に向いています。生成結果をプログラムで扱えるので、たとえば「シナリオを自動で分割 → 各カットのイメージを生成 → 動画に変換」といった高度なパイプライン構築も可能です。
Vertex AI(Gemini API)のセットアップ手順案
1. Google Cloud の準備
- Google Cloud Console にログイン
- 新規プロジェクトを作成(例:
gemini-flash-demo) - 課金を有効化(無料枠もあるがクレカ登録は必須)
2. API とライブラリの有効化
- サイドメニュー → 「APIとサービス」 → 「ライブラリ」
Vertex AI APIを検索して有効化- ついでに
IAMでサービスアカウントを作成しておくとスムーズ
3. 開発環境の準備
ローカル or サーバーに SDK を入れる。
# gcloud CLI インストール(Linux例)
curl https://sdk.cloud.google.com | bash
exec -l $SHELL
gcloud init
Node.js や Python SDK も選べます。
- Python:
pip install google-cloud-aiplatform - Node.js:
npm install @google-cloud/vertexai
4. 認証設定
サービスアカウントキーを発行して環境変数に指定。
export GOOGLE_APPLICATION_CREDENTIALS="~/keys/gemini-vertex.json"
5. サンプルコード(Python)
from google.cloud import aiplatform
from vertexai.preview.vision_models import ImageGenerationModel
# モデルの読み込み
model = ImageGenerationModel.from_pretrained("gemini-2.5-flash-image")
# プロンプトから画像生成
prompt = "a cyberpunk city at night, neon lights, high detail"
image = model.generate_images(prompt=prompt, number_of_images=1)
# 出力を保存
image[0].save("output.png")
6. 注意点
- デフォルトのリージョンは
us-central1など → 日本から使うならレイテンシを考慮 - 無料枠はあるが、画像生成はすぐに上限に達することが多い
- APIキーを GitHub 等に公開しないよう注意
(3) Adobe Firefly / Express 連携
一般クリエイターにとって最も身近になるのが、この Adobe 製品との統合です。 すでに Firefly では Gemini 2.5 Flash Image が組み込まれ、写真やイラストを自然言語で編集できるようになっています。さらに Adobe Express では、その画像をそのままポスターや動画に落とし込めるので、商用利用のスピード感が段違いです。無料枠で 20生成まで体験可能なのもポイントです。
実際に試すなら…
- 「まずはAI Studioで感触を掴む」
- 「用途が見えたら Vertex AI で自動化」
- 「商用クリエイティブなら Firefly/Express」
という流れが現実的だと思います。
👉 次章では、実際にどんなことができるのか――基本機能の使い方と実例を紹介していきます。
3. 基本機能の使い方と実例
Gemini 2.5 Flash Image の魅力は、生成と編集を“会話感覚”で行えることにあります。従来の画像生成AIが「一発勝負」的なところがあったのに対し、このモデルは「作る→修正→仕上げ」と自然にやりとりを重ねられるのが特徴です。
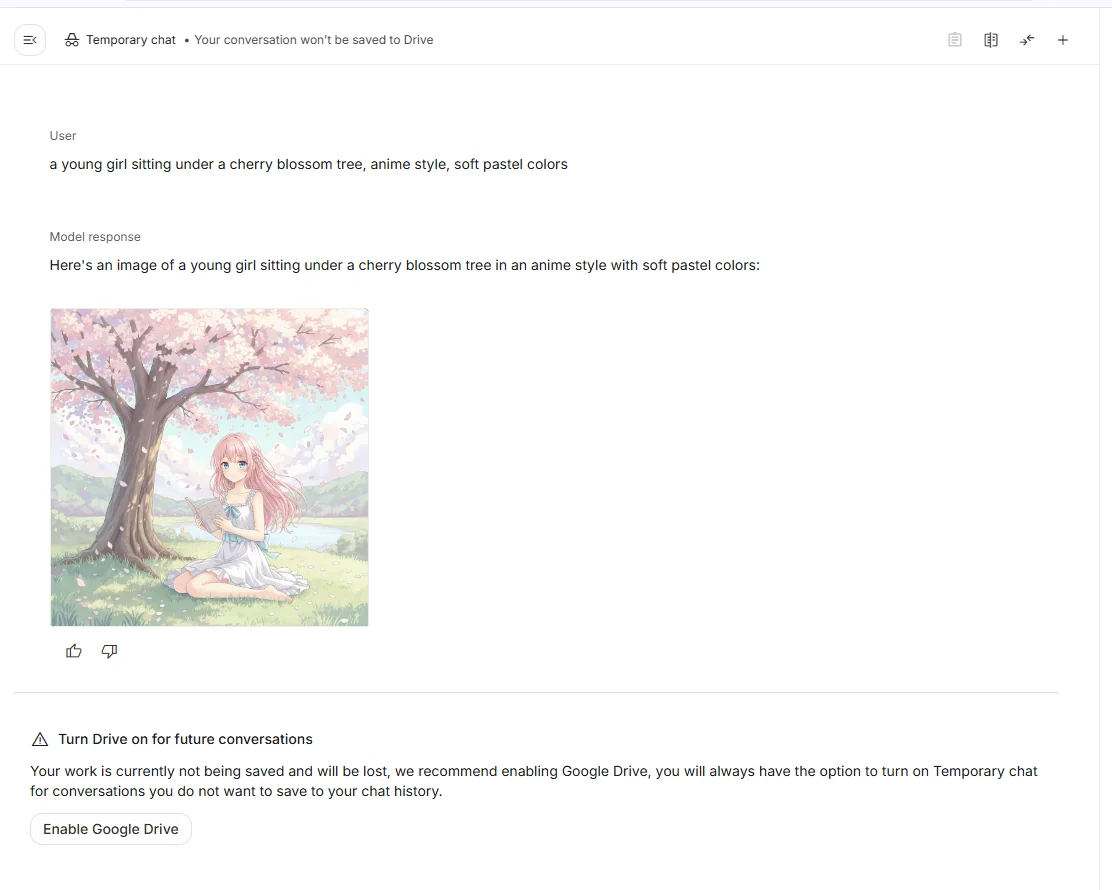
(1) テキストからの画像生成
もっとも基本的な使い方は、プロンプトを入力して画像を生成する方法です。
たとえば:
a young girl sitting under a cherry blossom tree, anime style, soft pastel colors
これだけで桜の下に座る少女のイラストが生成されます。 Stable Diffusion と比べると「破綻の少なさ」「キャラの統一感」が際立ち、短い文章でも安定した出力が得られるのが印象的です。

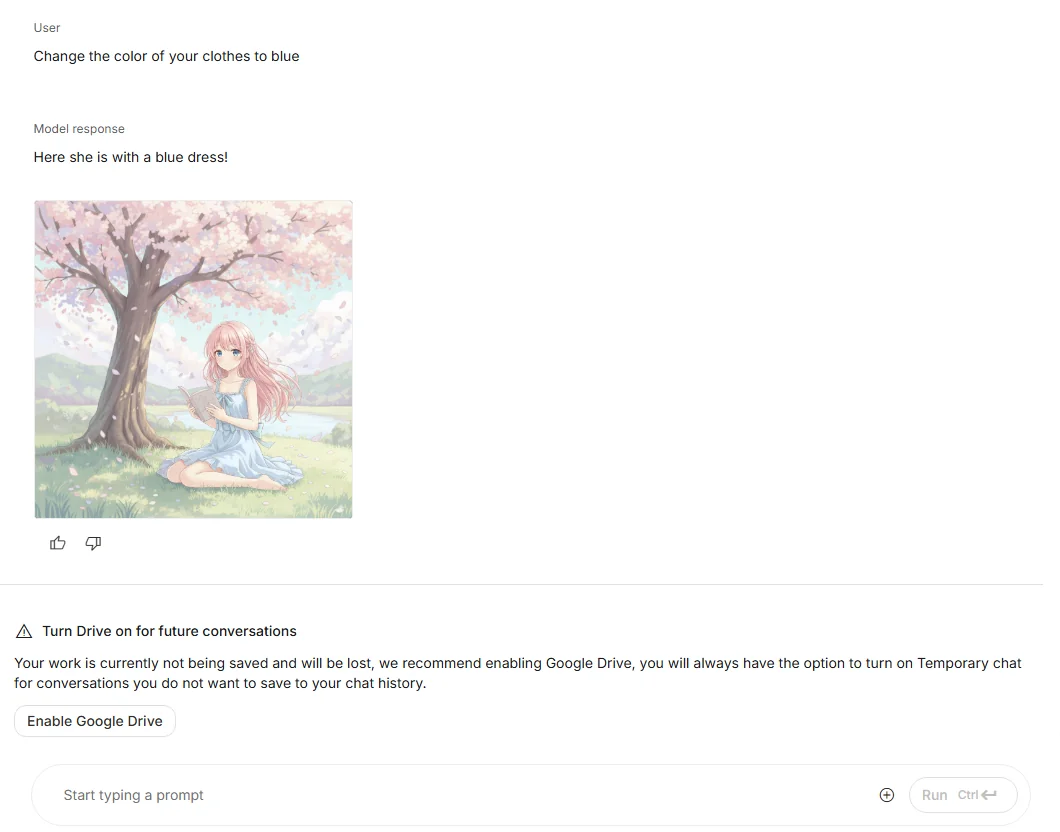
(2) 自然言語による画像編集
生成後の画像に対して、以下のような修正を加えられます。
- 「背景をぼかして」
- 「服の色を青に変えて」
- 「犬を消して猫に置き換えて」
従来なら Photoshop で複数レイヤーを操作する必要があった作業が、自然言語だけで完結します。ここが “AIとの会話で画像を作る”感覚を最も強く感じられる部分です。
Change the color of your clothes to blue

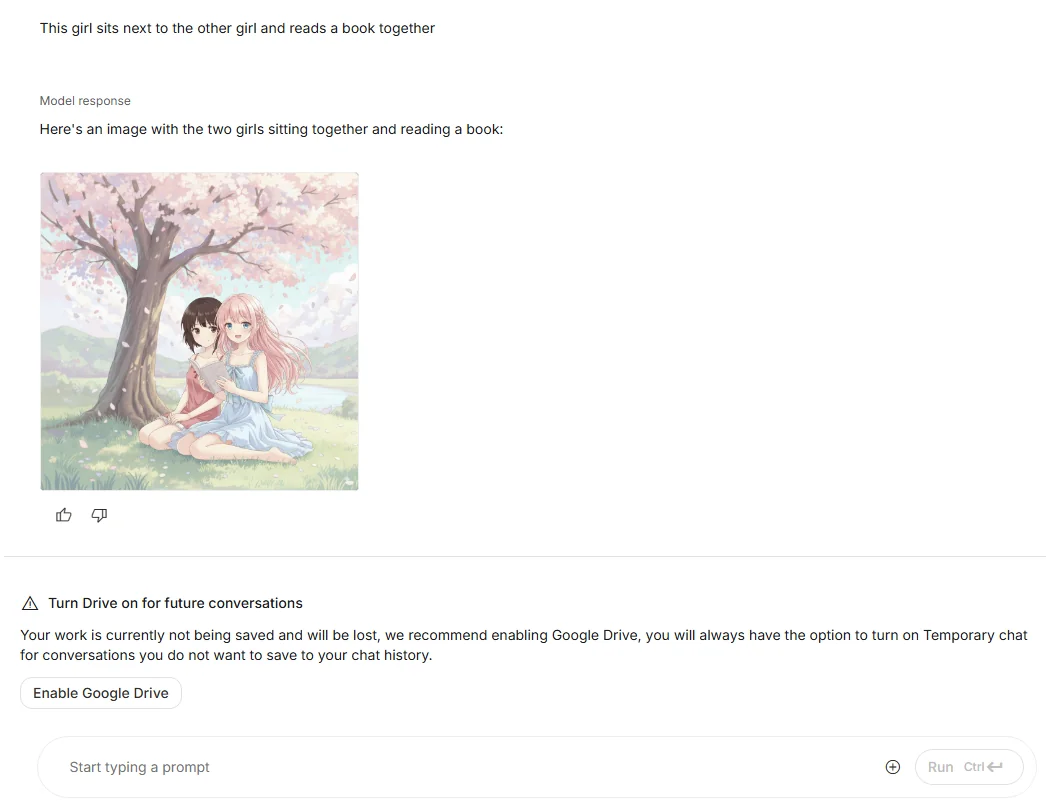
(3) マルチイメージフュージョン(画像融合)
Gemini 2.5 Flash Image のユニークな機能が 複数画像を融合して新しい画像を生成する機能です。 例えば:
- 「空室のリビング写真」+「椅子の写真」 → 椅子を置いた完成イメージ
- 「キャラクター立ち絵」+「背景写真」 → シーン付きの完成カット
これにより、プロダクトデザインや広告クリエイティブなど、実務的な用途に強みを発揮します。
This girl sits next to the other girl and reads a book together

(4) キャラクターの一貫性保持
一度生成したキャラクターを、別のシーンやポーズに登場させても、顔や服装の特徴が崩れにくいのも特徴です。 ストーリー仕立ての作品づくりでは特に有用で、漫画のコマ割りや短編アニメの各カット生成に応用できます。
The background is a school classroom, and a girl is sitting at a desk reading a book. A girl in red is standing and talking to another girl.
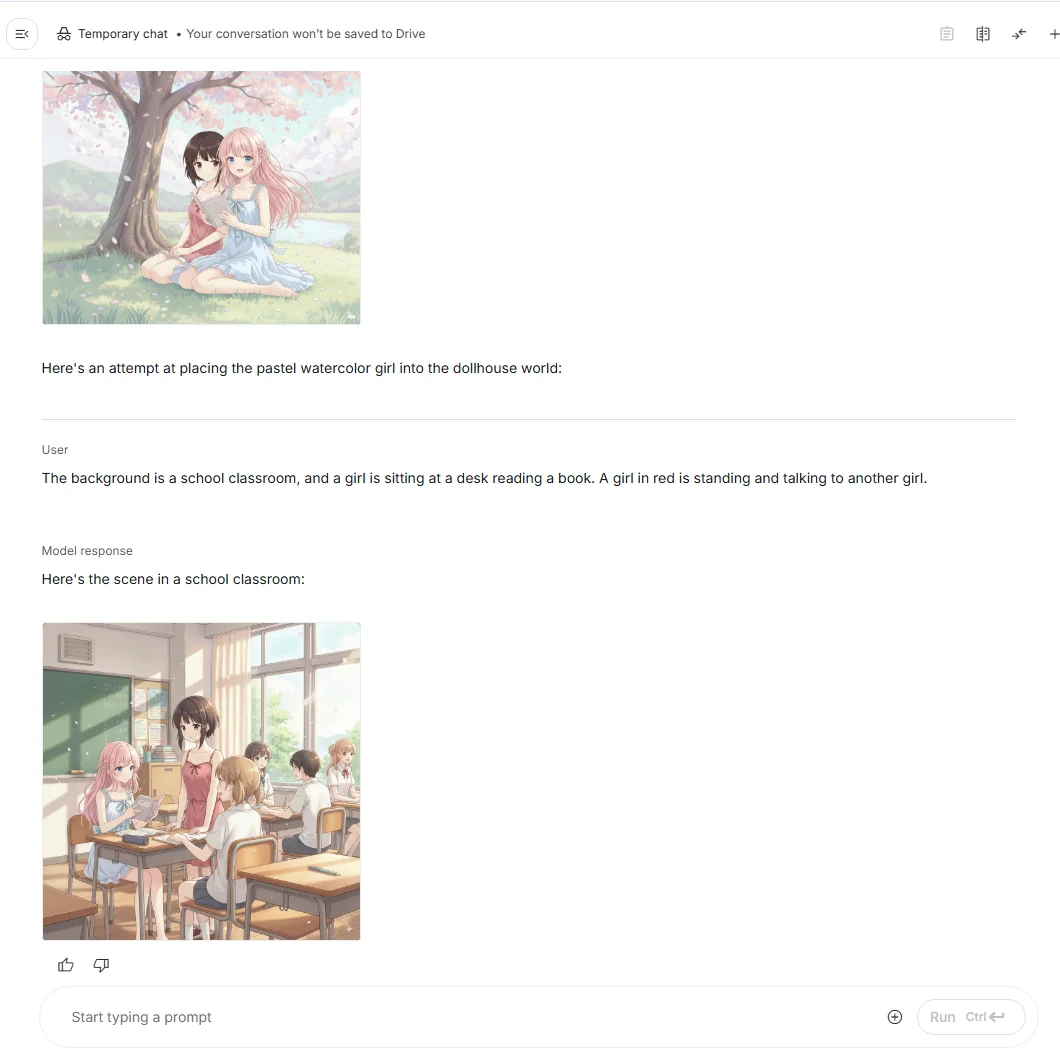

(5) 4コマ漫画を作成
昔の漫画にありがちな
1.登校中:主人公(普通の学生)が空を見上げる
2.落下:空から少女がドーン!
3.キャッチ:慌てて受け止める
4.空から降って来た異世界少女と共同生活開始
のプロンプトを作成。
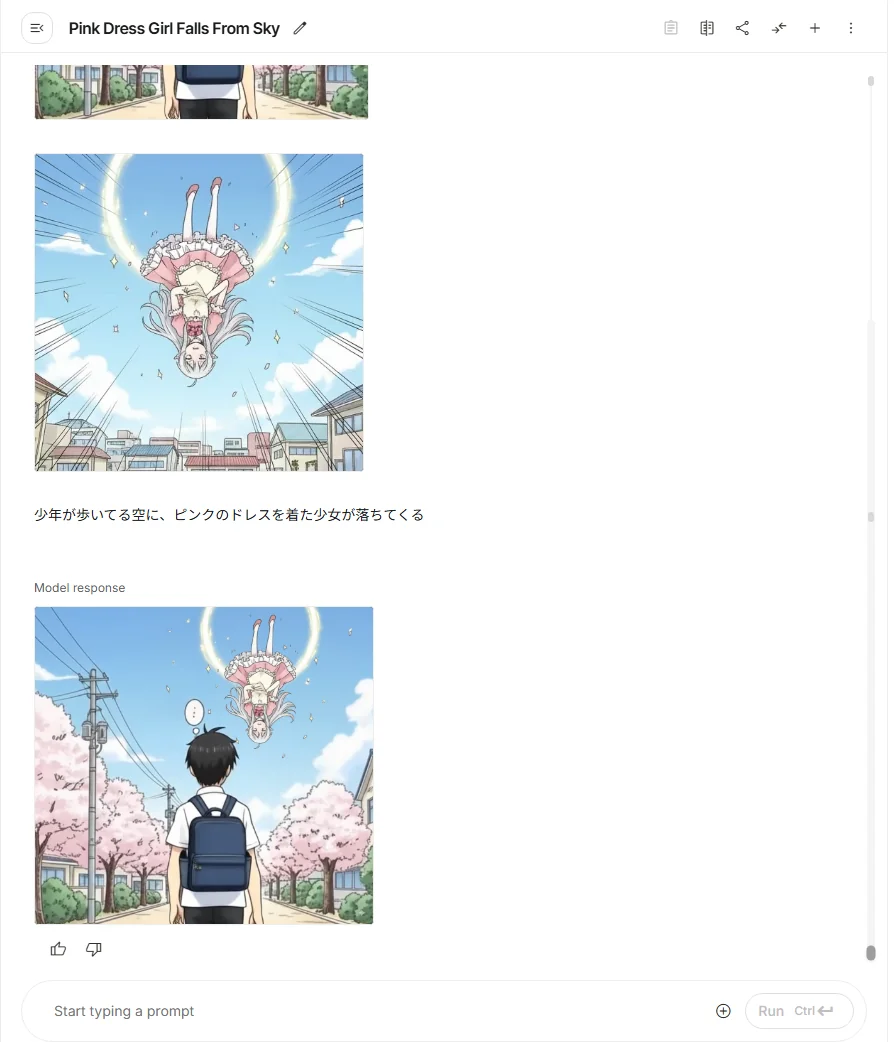
Create a four-panel comic with the following content:
1. On the way to school: The protagonist (a normal student) looks up at the sky.
2. Falling: A girl falls from the sky!
3. Catching: The protagonist quickly catches the girl.
4. The protagonist begins living together with a girl from another world who fell from the sky.
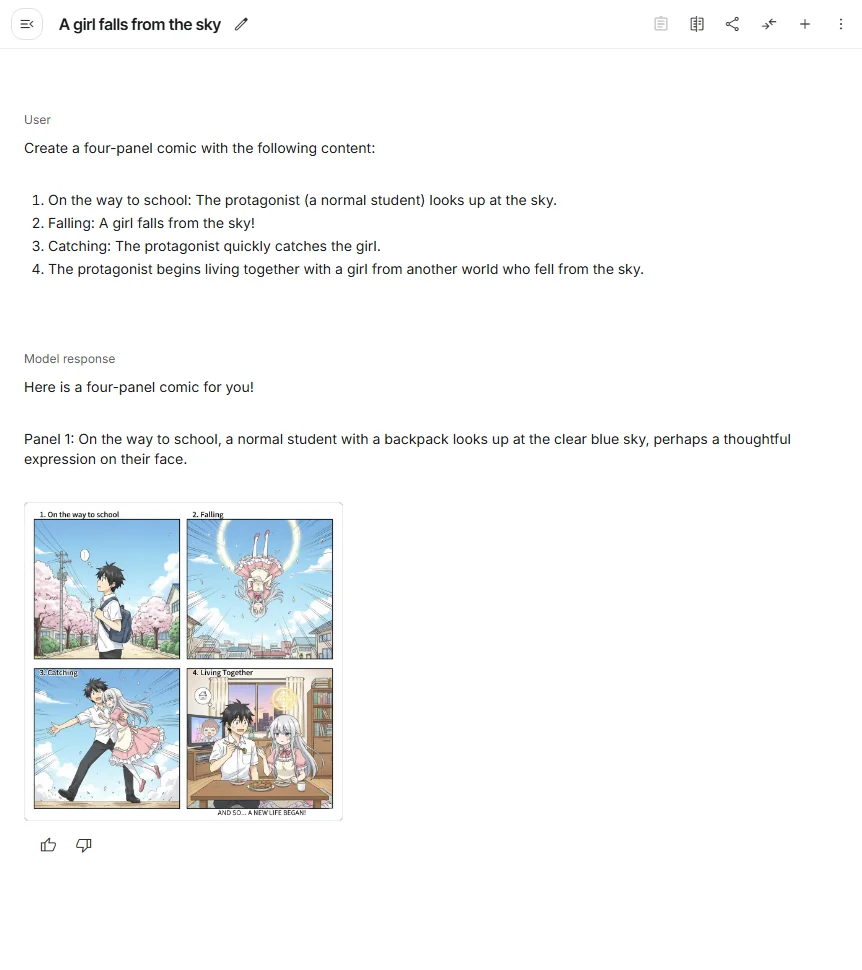
作成までにかかった時間は大体10秒ほどで、恐ろしく速い。
ちょっとしたアイデアが、即形になってしまうので、これは、楽しすぎますね…。

(6) 4コマ漫画をアニメ化
面白そうなので、作成した各コマをカットし、アニメ化してみました。
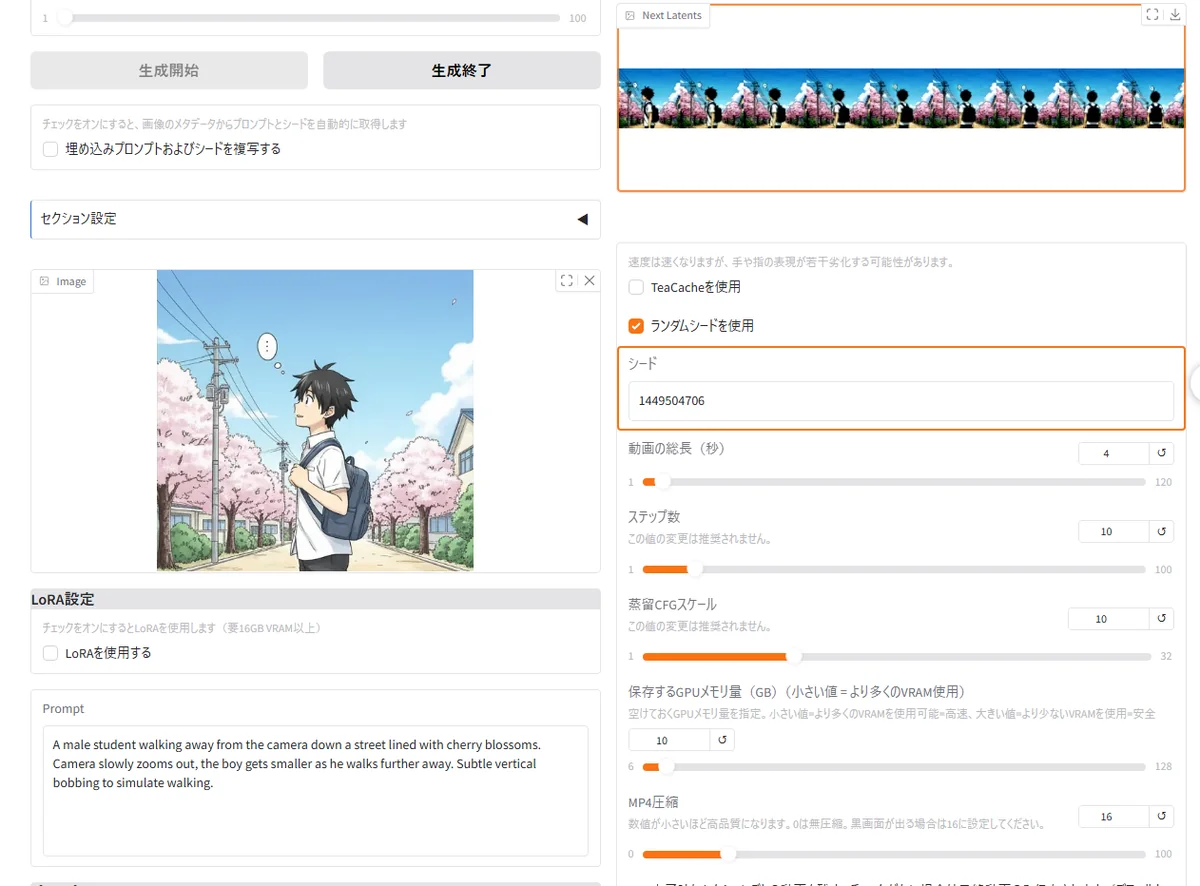
1. On the way to school: The protagonist (a normal student) looks up at the sky.
A male student walking away from the camera down a street lined with cherry blossoms. Camera slowly zooms out, the boy gets smaller as he walks further away. Subtle vertical bobbing to simulate walking.
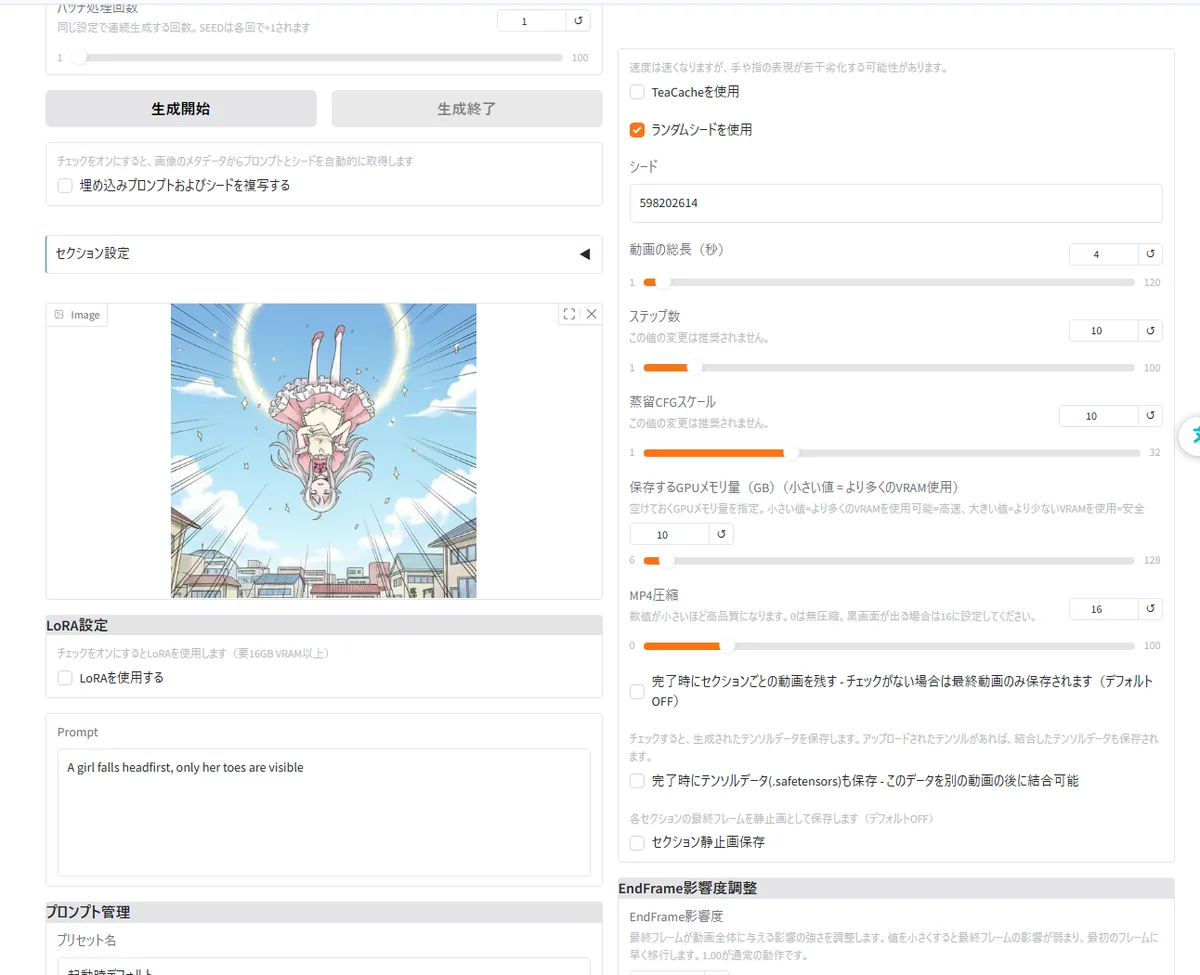
2. Falling: A girl falls from the sky!
A girl falls headfirst, only her toes are visible
3. Catching: The protagonist quickly catches the girl.
次のコマへ繋ぐのは、難しいので中間フレーム的な物を作成
A girl falls from the sky and a boy runs to catch her
キャッチ部分は少しだけアニメーション。
4. The protagonist begins living together with a girl from another world who fell from the sky.
ラストは食事シーン
At dinner time, the boy eats casually, while the elf girl from another world hesitantly pokes at a piece of fried food with chopsticks.
Her expression shows fear and curiosity at the strange Earth food.
(6) 動画を結合(完成)
ffmpegで繋いで完成。
C:\Users\username\github\my-blog\static\videos>(
More? echo file 'ai-gemini2_5-flash-image-01.mp4'
More? echo file 'ai-gemini2_5-flash-image-02.mp4'
More? echo file 'ai-gemini2_5-flash-image-03.mp4'
More? echo file 'ai-gemini2_5-flash-image-04.mp4'
More? echo file 'ai-gemini2_5-flash-image-05.mp4'
More? ) > list.txt
C:\Users\username\github\my-blog\static\videos>
C:\Users\username\github\my-blog\static\videos>ffmpeg -f concat -safe 0 -i list.txt -c copy output.mp4
ffmpeg version 7.1.1-full_build-www.gyan.dev Copyright (c) 2000-2025 the FFmpeg developers
built with gcc 14.2.0 (Rev1, Built by MSYS2 project)
configuration: --enable-gpl --enable-version3 --enable-static --disable-w32threads --disable-autodetect --enable-fontconfig --enable-iconv --enable-gnutls --enable-lcms2 --enable-libxml2 --enable-gmp --enable-bzlib --enable-lzma --enable-libsnappy --enable-zlib --enable-librist --enable-libsrt --enable-libssh --enable-libzmq --enable-avisynth --enable-libbluray --enable-libcaca --enable-libdvdnav --enable-libdvdread --enable-sdl2 --enable-libaribb24 --enable-libaribcaption --enable-libdav1d --enable-libdavs2 --enable-libopenjpeg --enable-libquirc --enable-libuavs3d --enable-libxevd --enable-libzvbi --enable-libqrencode --enable-librav1e --enable-libsvtav1 --enable-libvvenc --enable-libwebp --enable-libx264 --enable-libx265 --enable-libxavs2 --enable-libxeve --enable-libxvid --enable-libaom --enable-libjxl --enable-libvpx --enable-mediafoundation --enable-libass --enable-frei0r --enable-libfreetype --enable-libfribidi --enable-libharfbuzz --enable-liblensfun --enable-libvidstab --enable-libvmaf --enable-libzimg --enable-amf --enable-cuda-llvm --enable-cuvid --enable-dxva2 --enable-d3d11va --enable-d3d12va --enable-ffnvcodec --enable-libvpl --enable-nvdec --enable-nvenc --enable-vaapi --enable-libshaderc --enable-vulkan --enable-libplacebo --enable-opencl --enable-libcdio --enable-libgme --enable-libmodplug --enable-libopenmpt --enable-libopencore-amrwb --enable-libmp3lame --enable-libshine --enable-libtheora --enable-libtwolame --enable-libvo-amrwbenc --enable-libcodec2 --enable-libilbc --enable-libgsm --enable-liblc3 --enable-libopencore-amrnb --enable-libopus --enable-libspeex --enable-libvorbis --enable-ladspa --enable-libbs2b --enable-libflite --enable-libmysofa --enable-librubberband --enable-libsoxr --enable-chromaprint
libavutil 59. 39.100 / 59. 39.100
libavcodec 61. 19.101 / 61. 19.101
libavformat 61. 7.100 / 61. 7.100
libavdevice 61. 3.100 / 61. 3.100
libavfilter 10. 4.100 / 10. 4.100
libswscale 8. 3.100 / 8. 3.100
libswresample 5. 3.100 / 5. 3.100
libpostproc 58. 3.100 / 58. 3.100
[mov,mp4,m4a,3gp,3g2,mj2 @ 0000023d3fcc8040] Auto-inserting h264_mp4toannexb bitstream filter
Input #0, concat, from 'list.txt':
Duration: N/A, start: 0.000000, bitrate: 1322 kb/s
Stream #0:0(und): Video: h264 (Main) (avc1 / 0x31637661), yuv420p(progressive), 640x608 [SAR 1:1 DAR 20:19], 1322 kb/s, 30 fps, 30 tbr, 15360 tbn
Metadata:
handler_name : VideoHandler
vendor_id : [0][0][0][0]
encoder : Lavc61.3.100 h264_nvenc
Stream mapping:
Stream #0:0 -> #0:0 (copy)
Output #0, mp4, to 'output.mp4':
Metadata:
encoder : Lavf61.7.100
Stream #0:0(und): Video: h264 (Main) (avc1 / 0x31637661), yuv420p(progressive), 640x608 [SAR 1:1 DAR 20:19], q=2-31, 1322 kb/s, 30 fps, 30 tbr, 15360 tbn
Metadata:
handler_name : VideoHandler
vendor_id : [0][0][0][0]
encoder : Lavc61.3.100 h264_nvenc
Press [q] to stop, [?] for help
[mov,mp4,m4a,3gp,3g2,mj2 @ 0000023d3fcda740] Auto-inserting h264_mp4toannexb bitstream filter
Last message repeated 3 times
[out#0/mp4 @ 0000023d3fcae140] video:2416KiB audio:0KiB subtitle:0KiB other streams:0KiB global headers:0KiB muxing overhead: 0.303087%
frame= 505 fps=0.0 q=-1.0 Lsize= 2424KiB time=00:00:16.73 bitrate=1186.5kbits/s speed= 542x
無理やり繋いだので完成度はかなり低いですが、実験的に作ったので、その辺りはご了承ください。
動画編集アプリで編集した方が格段に品質は良くなると思います。
多少作り直したとはいえ、漫画のアイデア出しから、アニメーション作成まで数時間程度で出来たので、時間と手間さえかけるとそれなりの物が作れると思います。
アイデアと根気、ツールを使いこなすスキルさえあれば一人で何でもできてしまう時代ですね。
実際に使ってみると
- 一発生成でも完成度が高く、**「直すためにAIを使う」ではなく「最初から安定して作る」**感覚に近い
- 編集プロンプトが素直に通るため、試行錯誤のストレスが少ない
- 逆に、ランダム性や“予想外のカオス感”はやや薄め。これは「安定感と偶然性のトレードオフ」と言えるかもしれません
👉 次章では、実際に触ってわかったことを中心に、実践レビュー:使ってみた感想をまとめます。
4. 実践レビュー:使ってみた感想
実際に Gemini 2.5 Flash Image を使ってみると、**「速い・安定・直感的」**という3つのキーワードがすぐに浮かびました。以下、具体的な所感を整理します。
(1) 生成速度とレスポンス
とにかく反応が速い。Stable Diffusion をローカルで回した時に比べ、クラウド環境で動作しているにも関わらず生成までの待ち時間が短いです。数秒単位で結果が返ってくるので、作業のリズムを保ちやすい。
→ 「待たされるストレスが少ない」のは思った以上に大きなメリットでした。
(2) 出力品質と安定感
キャラクターや構図の崩れが少なく、プロンプトが短めでも安定した出力が得られるのが印象的。特に人物の顔や手が破綻しにくいのは強みです。 ただし裏を返すと、やや「無難」な出力に収まりやすく、尖ったカオス感を狙いたい人には物足りないかもしれません。
(3) 編集体験の快適さ
生成した画像に対して、「服の色を青に」「背景を少しぼかして」と自然言語で指示するだけで、ほぼ期待通りに修正されました。 従来の「再生成ガチャ」を繰り返すのではなく、画像を少しずつブラッシュアップしていける感覚は、新しい体験です。
(4) 偶然性=“AIガチャ”の残存
もちろん「完全に意図通り」ではなく、プロンプトを同じにしても少しずつ差が出ます。これは欠点でもありますが、逆に新しいアイデアや偶然の演出が生まれる楽しさも残っていて、良いバランスだと感じました。
(5) 実用性と制限
- 実用面では、広告ビジュアルやプレゼン資料の作成にすぐ使える完成度
- 制限としては、細部のコントロールや自由度はまだ限定的で、Stable Diffusion のような「ノードベースの徹底的な調整」と比べると物足りなさもあり
総合評価
Gemini 2.5 Flash Image は、**「AIに丸投げして偶然に賭ける」**という従来の生成AIとは違い、 **「AIと会話しながら少しずつ仕上げていく」**方向に進化したモデルだと感じました。
- ✅ スピード感と安定性を求める人には強力な武器
- ✅ 創作の偶然性を完全に捨てたくない人にも程よくフィット
- ❌ 徹底的な自由度や細部調整を求める場合は物足りない
👉 次章では、Stable Diffusion や ComfyUI、Adobe Firefly との比較を通じて、Gemini 2.5 Flash Image の立ち位置を整理します。
5. 他モデルとの比較
Gemini 2.5 Flash Image の評価をより明確にするために、既存の代表的な画像生成ツールと比較してみます。
(1) Stable Diffusion(+ComfyUI)との比較
- 自由度 Stable Diffusion はノード構成やLoRA/ControlNetによる微調整など、きめ細かい制御が可能。カオスや尖った出力を狙うならこちらが強い。
- 安定性 Gemini の方が初期出力の安定度は高く、手や顔の崩壊が少ない。短いプロンプトで完成度の高い画像が出る。
- 速度 Stable Diffusion はローカル環境次第。VRAM不足や設定の最適化が必要だが、Gemini はクラウド前提なので常に高速。
- 学習コスト SD+ComfyUI はノード設計を理解するまでに時間がかかる。Gemini は自然言語だけで操作できるため学習ハードルが低い。
(2) Adobe Firefly / Express との比較
- 統合性 Firefly 上で Gemini 2.5 Flash Image が動作しているため、生成→編集→デザイン出力まで一気通貫で進められる。
- ユーザー層 Photoshop や Illustrator のような専門ツールに慣れていない人でも扱えるので、商用クリエイティブ初心者にとっても参入障壁が低い。
- 制限 商用利用ライセンスやウォーターマーク(SynthID)などの透明性管理が標準で付与される。逆に言えば、実験的な出力を完全自由に扱うにはやや制限が多い。
(3) 実際の立ち位置
- Stable Diffusion …「自由度とカスタマイズの王様」
- ComfyUI …「プロの研究者・開発者向けのラボ環境」
- Adobe Firefly …「商用クリエイティブの実用ライン」
- Gemini 2.5 Flash Image …「会話感覚で高速・安定生成する新基準」
Gemini は「自由度はそこまで高くないが、スピードと安定感で日常使いに最適」というポジションにいます。特に**“AIと会話しながら創る”感覚**は、他のモデルにはない大きな強みです。
👉 次章では、こうした比較を踏まえて、実際の用途と活用アイデアを整理していきます。
6. 用途と活用提案
Gemini 2.5 Flash Image は「速い」「安定している」「会話で修正できる」という特性を持っています。これを踏まえると、次のような分野での活用が現実的かつ有効です。
(1) クリエイティブ制作の加速
- キャラクタービジュアルの連続生成 一度生成したキャラクターを別シーンに登場させても特徴が崩れにくいため、漫画のコマ割りやアニメ用カット生成に向いています。
- 広告/プロモーション画像 商品写真と背景を融合してシーンを作るなど、制作現場でありがちな「合成作業」を自然言語だけで完結可能。
- プレゼンやブログ用の図解素材 シンプルなダイアグラムやイメージ図を、わざわざグラフィックツールを開かなくても素早く作成できます。
(2) 学習・教育用途
- 教材の図解生成 歴史・科学・文学の場面を簡単にビジュアライズ可能。教育資料に彩りを加えるのに便利。
- 手書きスケッチの清書 簡単なラフをアップロードして「綺麗な図にして」と依頼すれば、見栄えのする教材画像に変換できます。
(3) プロトタイピング&アプリ連携
- UI/UX プロトタイプ作成 Webアプリやモバイルアプリのモックアップに、仮の背景やアイコンを即座に生成して使える。
- AIアニメーションへの応用 Pythonなどのコードから各シーン画像を生成し、それをつなぎ合わせて動画化するワークフロー(lainさんが取り組んでいるスタイル)に直結。
(4) 個人活用
- 断酒や学習記録の可視化 「今日の気分をイメージ化」する、といった遊び心ある日記にも。
- ブログのアイキャッチ作成 記事テーマを入力するだけで、それっぽいヘッダー画像が出せるので執筆作業が効率化。
提案まとめ
Gemini 2.5 Flash Image は「本格的な創作にも、日常的な補助にも」向いているツールです。 特に 「キャラを一貫させたい」「合成を素早くやりたい」「会話感覚で修正したい」 という場面では、従来ツールより圧倒的に時短効果を発揮します。
👉 次章では、こうした体験を踏まえ、今後への期待と改善してほしい点を整理します。
承知しました!では第7章「今後の期待と改善希望」をまとめますね。
7. 今後の期待と改善希望
Gemini 2.5 Flash Image はすでに実用レベルの完成度を持っていますが、実際に使ってみると「ここが伸びたらもっとすごい」と思う点も見えてきました。
(1) 精度向上と細部コントロール
- 現状でも人物や構図は安定していますが、**細かいディテール(手の指・文字・複雑な背景パターン)**ではまだ不自然さが残ることがあります。
- Stable Diffusion のような「ControlNet的な局所制御」が組み込まれると、プロレベルの用途にもさらに踏み込みやすくなるでしょう。
(2) 自由度と偶然性のバランス
- Gemini は「安定感」に寄せているため、予想外の“カオス”が出にくいのは弱点でもあります。
- 「安定モード」と「ランダムモード」を切り替えられるようになれば、作品の幅が大きく広がるはずです。
(3) API/開発者向けの改善
- 現状でも Vertex AI から利用可能ですが、生成履歴の管理や編集プロンプトのバージョン管理など、開発フローに組み込みやすい仕組みが欲しいところ。
- これが整えば、lainさんが構想しているような「Pythonスクリプトで各カット生成→アニメーション化」のワークフローがもっとスムーズになります。
(4) 利用環境の拡大
- Adobe Firefly や Express に統合されつつありますが、Canva や Figma などのデザインツール、Notion や Obsidian のようなナレッジ管理アプリにも連携すれば、日常的な利用が一気に広がるでしょう。
(5) コミュニティとナレッジ共有
- Stable Diffusion がここまで成長したのは「ユーザーのプロンプト知見共有」のおかげです。
- Gemini でも **「このプロンプトでこう変わった」という公開例が増える」ことで、学習曲線が短くなり、利用者が一気に増えると期待されます。
まとめ
Gemini 2.5 Flash Image は 「速さ」「安定性」「直感的な会話編集」 という強みをすでに持ち、日常的なクリエイティブ作業に大きな価値を提供しています。 今後、細部制御・偶然性の選択・開発者支援・利用環境の拡張が整えば、Stable Diffusion と並ぶか、あるいはそれを凌駕する存在になるかもしれません。
💬 コメント